
 Автор:
Автор: Линейка видеокарт GeForce 50 разворачивается в привычном направлении от флагмана, который является не только игровым, но и просьюмерским решением, к устройствам для энтузиастов и, с изрядной задержкой, продуктам среднего уровня. Мы же по логистическим причинам вынуждены задержать тестирование GeForce RTX 5090 и начать серию обзоров с RTX 5080, что по-своему удачно. Уникальная близость второй модели к своему предшественнику, RTX 4080 SUPER, по формальным характеристикам позволит нам взвесить преимущества новой архитектуры Blackwell и понять, почему вместе с поколениями GPU теперь не меняется не только цена одного FPS, но и, в определенных условиях, чистая производительность.
GeForce RTX 5080 представляет в обзоре видеокарта Palit GameRock.
⇡#Графические процессоры GB20X
В новом поколении графических процессоров NVIDIA снова устранила формальное разделение на две ветки архитектуры — ускорители для дата-центров, с одной стороны, и продукты для игровых ПК и рабочих станций, с другой. HPC-решения по-прежнему имеют ряд количественных и функциональных отличий от массовых GPU, но и те и другие принадлежат к одной линейке Blackwell, названной в честь американского математика Дэвида Блэквелла.
Чипы выходят с линии TSMC 4NP, которая представляет собой второй по счету вариант 5-нанометрового техпроцесса, адаптированный к запросам NVIDIA, в то время как Apple и Intel уже заказывают большие кристаллы, выполненные по норме 3 нм. Справедливости ради отметим, что дискретная графика конкурентов тоже оказалась не готова к миграции на 3 нм, но у этих компаний есть большой резерв для роста удельной производительности GPU за счет архитектурных изменений (что уже продемонстрировали ускорители Arc второго поколения). Да и вообще AMD и Intel пока не намерены соревноваться с «зелеными» в высшем эшелоне цены и быстродействия. А вот для NVIDIA задержка на старом фотолитографическом узле стала тем решением, которое в конечном счете определило облик видеокарт GeForce 50-й серии.
В данный момент полностью известны характеристики трех потребительских GPU семейства Blackwell, которые легли в основу десктопных моделей нового поколения, начиная с GeForce RTX 5070 и заканчивая RTX 5090. Как мы увидим впоследствии, сама логика графических процессоров NVIDIA не претерпела структурных изменений, поэтому количественное сравнение блочных формул старых и новых чипов вполне уместно и говорит многое об их «сырой» производительности.
| Производитель | NVIDIA | |||||
|---|---|---|---|---|---|---|
| Название | AD104 | AD103 | AD102 | GB205 | GB203 | GB202 |
| Где используется | RTX 4070; RTX 4070 SUPER; RTX 4070 Ti | RTX 4070 Ti SUPER; RTX 4080; RTX 4080 SUPER | RTX 4090 D; RTX 4090 | RTX 5070 | RTX 5070 Ti; RTX 5080 | RTX 5090 |
| Архитектура | Ada Lovelace | Blackwell | ||||
| Техпроцесс, нм | TSMC 4N | TSMC 4NP | ||||
| Число транзисторов, млрд | 35,8 | 45,9 | 76,3 | 31,0 | 45,6 | 92,2 |
| Площадь чипа, мм2 | 295 | 378,6 | 608,6 | 263 | 378 | 750 |
| Число SM/TPC/GPC | ||||||
| Streaming Multiprocessors (SM) | 60 | 80 | 144 | 50 | 84 | 192 |
| Thread Processing Clusters (TPC) | 30 | 40 | 72 | 25 | 42 | 96 |
| Graphics Processing Clusters (GPC) | 5 | 7 | 12 | 5 | 7 | 12 |
| Конфигурация потокового мультипроцессора (SM) | ||||||
| Векторные ALU (FP32/INT32) | 4 × 16 (FP32) + 4 × 16 (FP32/INT32) | 8 × 16 | ||||
| Векторные ALU (FP64) | 2 | |||||
| Скалярные ALU | 4 | |||||
| ALU специального назначения (SFU) | 4 × 4 | |||||
| Тензорные ядра | 4 × 1 | |||||
| RT-ядра | 1 | |||||
| Блоки наложения текстур (TMU) | 4 | |||||
| Объем регистрового файла, Кбайт | 256 | |||||
| Объем кеша L1/разделяемой памяти, Кбайт | 128 | |||||
| Вычислительные блоки GPU | ||||||
| Векторные ALU (FP32) | 7 680 | 10 240 | 18 432 | 6 400 | 10 752 | 24 576 |
| Тензорные ядра | 240 | 320 | 576 | 200 | 336 | 768 |
| RT-ядра | 60 | 80 | 144 | 50 | 84 | 192 |
| Блоки наложения текстур (TMU) | 240 | 320 | 576 | 200 | 336 | 768 |
| Блоки операций растеризации (ROP) | 80 | 112 | 192 | 64 | 192 | 192 |
| Конфигурация памяти | ||||||
| Объем кеша L2, Мбайт | 48 | 64 | 96 | 48 | 64 | 128 |
| Разрядность шины VRAM, бит | 192 | 256 | 384 | 192 | 256 | 512 |
| Тип микросхем VRAM | GDDR6X SGRAM | GDDR7 SGRAM | ||||
| Шина PCI Express | 4.0 x16 | 5.0 x16 | ||||
Флагманский кристалл GB202 поставил новый рекорд транзисторного бюджета среди потребительских GPU — 92,2 млрд, — который сближает его с HPC-чипом линейки Blackwell, GB100. Последний состоит из 104 млрд транзисторов и, по утверждению NVIDIA, исчерпывает размер фотошаблона TSMC. В свою очередь, площадь 750 мм2 ставит GB202 на второе место после TU102 (754 мм2) семейства Turing.
Вычислительные ресурсы включают 192 потоковых мультипроцессора, что в условиях неизменного распределения ALU по отдельным SM означает 24 576 FP32-совместимых CUDA-ядер. Чтобы насытить данными такой массив исполнительных блоков, GB202 наделили 128 Мбайт кеша последнего уровня и — внимание — 512-битным интерфейсом VRAM. Настолько широкой шины видеопамяти в сочетании с микросхемами GDDR SGRAM мы не видели со времен «красных» чипов Hawaii/Grenada (серия Radeon R 200/300).
Несмотря на впечатляющие характеристики GB202, заметно, что кремнию Blackwell тесно в границах технологии TSMC 4NP. Ранее переход от архитектуры Ampere к Ada Lovelace, который совпал с полноценным апгрейдом фотолитографической нормы, позволил нарастить вычислительную мощность старшего GPU в линейке на 72 % даже без учета тактовых частот. В свою очередь, GB202 превосходит предшественника — AD102 — лишь на 33 % по формуле шейдерных ALU.
Как бы то ни было, GB202 поднимет планку игрового быстродействия на новую высоту и в неменьшей степени рассчитан на профессиональные задачи, которым пойдет на пользу даже умеренный прогресс. К сожалению, того же нельзя сказать о характеристиках следующего по старшинству кристалла Blackwell. GB203 вдвое меньше флагманского GPU — как по числу транзисторов, так и по площади кристалла, — а в конфигурации вычислительных блоков (84 SM и 10 752 вещественночисленных ALU стандартной точности) недалеко ушел от соответствующей модели Ada Lovelace, AD103. Разрыв между графическими процессорами первого и второго эшелона в серии Blackwell как никогда велик и составляет 129 % программируемых вычислительных ресурсов! GB202 вслед за AD103 получил 256-битную шину видеопамяти и 64 Мбайт кеша L2.

Наконец, Blackwell не предлагает прямой замены чипу AD104, а ближайший по характеристикам GB205 обладает такой же конфигурацией последних ярусов стека памяти (48 Мбайт кеша L2 и 192-битная шина VRAM), но заметно меньшим числом SM и CUDA-ядер FP32: 50 и 6 400 соответственно.
Сравнение старых и новых GPU показывает, что NVIDIA удалось разместить чуть больше шейдерных ALU на квадратном миллиметре кремния, но техпроцесс TSMC 4NP не принес ни малейшего увеличения средней плотности транзисторов (в каждом эшелоне она даже немного снизилась), что прямо сказывается на стоимости производства и, в конечном счете, розничных ценах видеокарт.
⇡#Энергосберегающие функции Blackwell
Другой проблемой Blackwell, которая проистекает из фотолитографии TSMC 4NP, является энергопотребление. Чипы Ada Lovelace обладают лидирующей производительностью на ватт среди GPU прошлого поколения, но абсолютные величины потребляемой мощности в 50-й серии резко увеличились. К счастью, инженеры NVIDIA приняли целый ряд мер для того, чтобы обуздать «жор».

Отключение неиспользуемых блоков от генератора частоты (Clock Gating) происходит раньше и более избирательно, чем в чипах Ada Lovelace. Blackwell также использует раздельные линии питания вычислительных ядер GPU и системы памяти, что дает возможность индивидуальной подстройки напряжения под те или иные сценарии нагрузки или полного обесточивания вычислительных ядер с целью предотвратить утечки. К сожалению, NVIDIA не уточняет, какие структуры в данном случае называются ядрами (TPC, GPC или SM), но известно, что отключение/включение может происходить со скоростью смены кадров.
Как следствие этих нововведений, кремний Blackwell способен намного быстрее регулировать потребляемую мощность в ответ на изменение нагрузки, а задержка перехода из самого экономичного активного режима в глубокий сон уменьшилась на порядок. Согласно оценке NVIDIA, в определенных кратковременных задачах Blackwell расходует на 50 % меньше энергии по сравнению с Ada Lovelace.
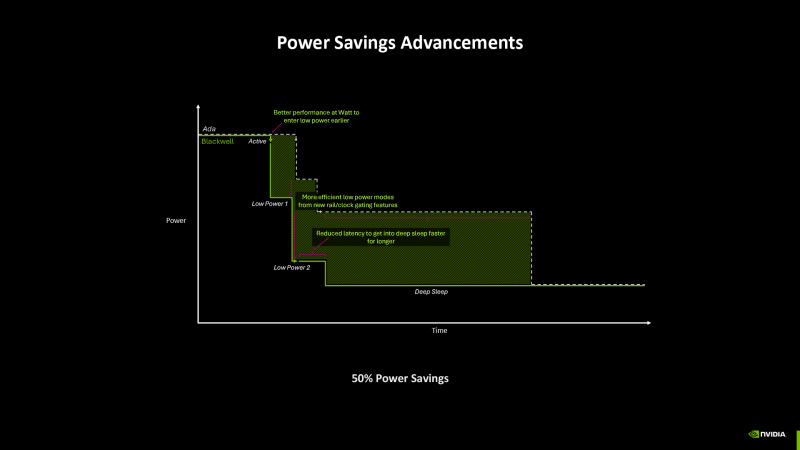
Кроме того, чипы Blackwell подчиняются новой системе контроля тактовой частоты. В прежних решениях NVIDIA вплоть до Ada Lovelace частота изменялась динамически, но была зафиксирована на время рендеринга одного кадра. Теперь временное разрешение регулировки частоты увеличено в 1000 раз, что позволяет GPU эффективно использовать резерв мощности или, наоборот, снизить энергопотребление в короткий период относительного бездействия (например, во время приема команд от центрального процессора).
⇡#Видеопамять GDDR7
Одним из титульных нововведений 50-й серии GeForce является поддержка видеопамяти GDDR7 SGRAM, которая обеспечивает максимальную пропускную способность 32 Гбит/с на контакт шины с перспективами вплоть до 48 Гбит/с. Новый стандарт VRAM отличается на физическом уровне как от широко распространенной памяти GDDR6, так и от GDDR6X, эксклюзивной для продуктов NVIDIA.
Интерфейс памяти SDRAM общего назначения и GDDR SGRAM вплоть до шестой версии кодирует сигнал при помощи амплитудно-импульсной модуляции с двумя уровнями сигнала (PAM2), а пропускная способность со времен перехода к DDR нарастала за счет увеличения символьной скорости (в бодах), которая предъявляет все более строгие требования к длине и разводке передающих линий. С этой проблемой столкнулись и другие высокопроизводительные интерфейсы, например PCI Express, USB и Ethernet, а общим решением является внедрение дополнительных уровней PAM.
Так, видеопамять GDDR6X, разработанная Micron в сотрудничестве с NVIDIA, различает четыре уровня сигнала и, следовательно, передает 2 бита информации за один цикл, что, однако, не привело к удвоению пропускной способности в практических условиях. Кодирование PAM4 особенно чувствительно к отношению «сигнал/шум», поэтому GDDR6X не может работать на столь же высокой символьной скорости, как GDDR6. В конце концов два стандарта пришли к одинаковой скорости передачи данных 24 Гбит/с, но GDDR6X отличается сложностью цепей физического уровня на обоих концах линии и повышенным энергопотреблением. Не говоря уже о том, что единственным заказчиком таких микросхем является NVIDIA, а поставщиком — Micron.
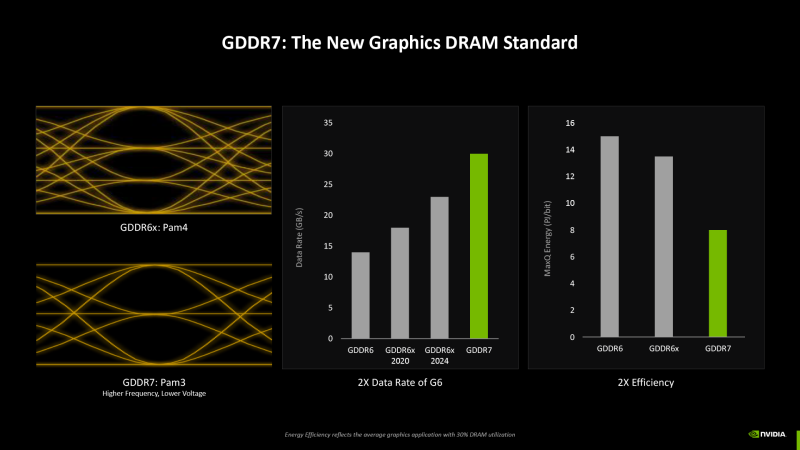
В отличие от GDDR6X, технология GDDR7 стандартизирована JEDEC, а к выпуску чипов уже приступили Micron, Samsung и SK hynix. Физический интерфейс GDDR7 в качестве компромиссного варианта между традиционным кодированием PAM2 и PAM4 использует три уровня сигнала (-1, 0 и +1) и передает 3 бита данных за два цикла. Таким образом удалось затормозить рост частоты шины VRAM, но вместе с тем и требования к отношению «сигнал/шум» у GDDR7 ниже по сравнению с GDDR6X. Кроме того, память GDDR7 поддерживает внутричиповую коррекцию ошибок (которая ранее стала обязательным атрибутом DDR5), имеет пониженное напряжение питания и функцию быстрого выхода из спящего режима. Максимальный объем чипа был увеличен с 32 до 64 Гбит (8 Гбайт), хотя до массового производства настолько плотных микросхем еще далеко. В контексте потребительских видеокарт более интересно, что допустимы небинарные объемы — такие как 24 Гбит.
⇡#PCI Express 5.0, видеокодек и вывод изображения
Кроме типа VRAM, графические процессоры NVIDIA опередили потребительские чипы конкурентов в миграции на системную шину PCI Express 5-го поколения, которая уже давно доступна в десктопных ПК, но освоена только твердотельными накопителями. Три старших GPU линейки Blackwell используют полную ширину интерфейса в 16 линий.
Наконец, произошли изменения в мультимедийном ASIC и контроллерах дисплея. GPU выполняет аппаратное кодирование и декодирование видео H.264 и HEVC с цветовой субдискретизацией YUV 4:2:2, которая обеспечивает лучшее разрешение цветности, нежели преобладающее в этих форматах кодирование YUV 4:2:0. Чипы Blackwell имеют два декодера NVDEC, как и Ada Lovelace, но, по оценкам NVIDIA, их скорость при работе с H.264, которая в предыдущем поколении была заметно ниже, чем при обработке HEVC и AV1, возросла вдвое. Что касается кодировщиков, то кристалл GB202 получил дополнительный блок NVENC вдобавок к прежним двум. И наконец, аппаратное кодирование AV1 дополнено новым режимом Ultra High Quality. Последний будет доступен и на железе 40-й серии, но Blackwell обеспечивает повышенное качество.
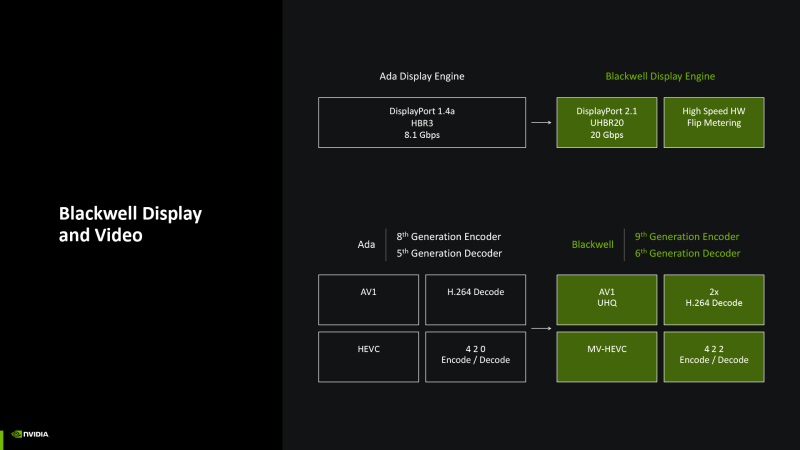
Контроллер дисплея совместим с последними версиями интерфейсов вывода изображения: HDMI 2.1b и DisplayPort 2.1b — в наивысшем режиме UHBR 20 (20 Гбит/с на линию и 80 Гбит/с при использовании всех четырех линий).
Вычислительная архитектура SM
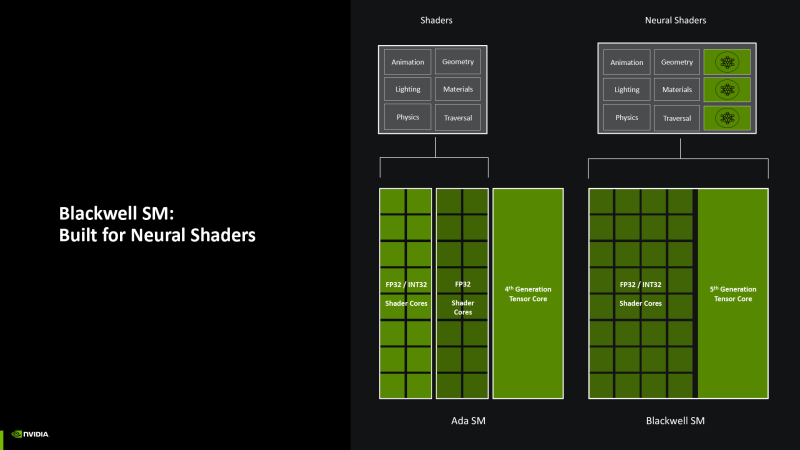
В то время как старший чип GB202 уравновешивает затянувшуюся остановку на фотолитографическом узле 5 нм громадными размерами и беспрецедентной потребляемой мощностью, графические процессоры следующих эшелонов могут полагаться только на оптимизацию архитектуры. Серия Blackwell привнесла в логику «зеленых» GPU больше усовершенствований, чем Ada Lovelace, и они носят скорее качественный, чем количественный характер.
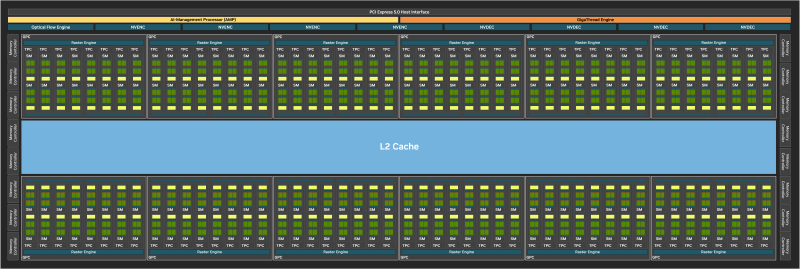
Высокоуровневая иерархия компонентов графического процессора не подвергается изменению со времен чипов Ampere. Крупнейшей масштабируемой единицей на блок-схеме является GPC (Graphics Processing Cluster), который объединяет все стадии конвейера рендеринга — от растеризатора, выполняющего проекцию геометрии в пикселы, до 16 блоков операций растеризации (ROP). Между ними расположен массив потоковых мультипроцессоров (SM), каждый из которых является формальным аналогом ядра центрального процессора — точно так же, как Compute Unit в графической архитектуре AMD и Xe-Core в чипах Intel.
Пары SM, привязанные к общему геометрическому движку, образуют промежуточную структуру TPC (Thread Processing Cluster). Число TPC внутри GPC варьирует от одного чипа к другому и достигает 16 во флагманском GB202.
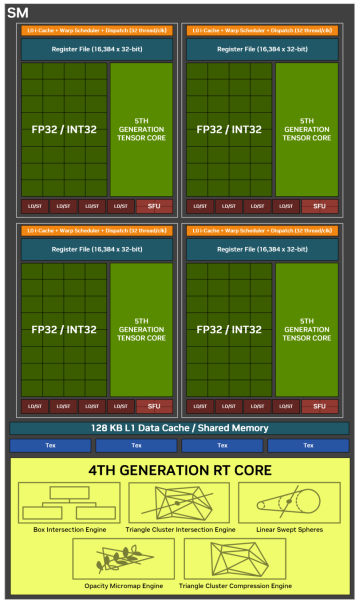
Наконец, сам потоковый мультипроцессор разделен на четыре подсекции (SM Subpartition, SMSP). Каждая из секций имеет собственный регистровый файл (наиболее скоростною часть стека памяти GPU), планировщик и диспетчер команд, к которому подключен ряд вычислительных блоков — в том числе тензорное ядро и две батареи из 16 шейдерных ALU (которые иначе можно назвать SIMD16, пользуясь терминологией AMD и Intel). Подробно о том, как работают графические процессоры NVIDIA на этом, самом низком, уровне, мы писали в теоретическом обзоре архитектуры Ampere. Следующая итерация кремния, Ada Lovelace не в несла в логику SM принципальных изменений.
Ключевая инновация Blackwell состоит в том, что, если раньше только один из двух SIMD16 мог выполнять целочисленные расчеты вместо операций над числами с плавающей запятой, теперь они функционально эквивалентны, а значит быстродействие GPU в чистых INT32-вычислениях удвоилось. Инструкции для операций над данными FP16 (не матричные) по-прежнему выполняются блоками SIMD16 без упаковки попарно, а значит, в таком же темпе, как FP32.
Совокупная пропускная способность четырех тензорных ядер SM задержалась на уровне 1 024 инструкции FMA с данными FP16 за один такт (которые раскладываются на 2 048 операций), но GPU теперь может обрабатывать вещественночисленные данные еще более низкой разрядности — FP4 — на пропорционально большей скорости, чем FP16 или FP8.
Кроме перечисленных вычислительных ресурсов, в SM есть четыре блока SIMD4, предназначенных для выполнения тригонометрических операций, четыре скалярных ALU и пара ALU двойной точности (FP64), которые гарантируют потребительским GPU базовую совместимость с подобным кодом. NVIDIA не сообщает ни о каких изменениях, связанных с этими второстепенными компонентами. Остался прежним и объем внутренних хранилищ: кеша L1 и регистрового файла.
Зато блоки наложения текстур, также являющиеся частью SM, научились вдвое быстрее производить точечную выборку, что не отражается на тексельном филлрейте с традиционной фильтрацией (билинейной, трилинейной, анизотропной), но важно для такой функции, как сжатие текстур при помощи нейросети (которой мы коснемся позже).
Таким образом, сырая производительность за такт работы SM по сравнению с Ada Lovelace увеличилась только в отношении целочисленных расчетов стандартной точности (INT32). Остались в силе и правила сосуществования разнородных нагрузок внутри отдельно взятой подсекции SM. INT32 отнимает пропускную способность у FP32, а диспетчер может отдать только одну инструкцию за такт какому-либо из нескольких типов вычислительных блоков, но благодаря латентности исполнения как минимум в два такта поддерживается параллелизм.
| Compute Unit (AMD RDNA 3) | Xe-core (Intel Xe2) | Streaming Multiprocessor (NVIDIA Ada Lovelace) | Streaming Multiprocessor (NVIDIA Blackwell) | |
|---|---|---|---|---|
| Исполнительные блоки |
2 × SIMD32 (FP32/INT32); 2 × SIMD32 (FP32); 2 × SIMD2 (FP64); 2 × SIMD8 (SFU); 2 × скалярных ALU |
8 × SIMD16 (FP32); 8 × SIMD16 (INT32); 8 × SIMD2 (FP64); 8 × SIMD4 (SFU); 8 × XMX |
4 × SIMD16 (FP32/INT32); 4 × SIMD16 (FP32); 2 × SISD? (FP64); 4 × SIMD4 (SFU); 4 × скалярных ALU; 4 × тензорных ядра |
8 × SIMD16 (FP32/INT32); 2 × SISD? (FP64); 4 × SIMD4 (SFU); 4 × скалярных ALU; 4 × тензорных ядра |
| Операции на линии SIMD за такт |
128 × FP32; 64 × INT32; 256 × FP16; 4 × FP64; 16 × трансц-е функции |
128 × FP32; 128 × INT32; 256 × FP16; 16 × FP64; 32 × трансц-е функции |
128 × FP32; 64 × INT32; 128 × FP16; 2 × FP64; 16 × трансц-е функции |
128 × FP32; 128 × INT32; 128 × FP16; 2 × FP64; 16 × трансц-е функции |
| Матричные операции, FLOP за такт (FP16) | 512 | 2 048 | 2 048 | 2 048 |
Графическая архитектура Intel Xe2 имеет ряд формальных преимуществ перед Blackwell. Так, целочисленные и вещественночисленные расчеты могут происходить параллельно на полной скорости, соответствующие ALU инициализируются за один такт вместе с матричным массивом XMX, а инструкции FP16 упаковываются попарно и исполняются в удвоенном темпе. Что касается «красных» ускорителей, то логика RDNA3 в теории развивает такую же пропускную способность FP32, как Blackwell, и вдвое быстрее работает с данными половинной точности. Однако набор инструкций RDNA резко сужает возможности для извлечения максимального параллелизма, не говоря уже о четырехкратном отставании от конкурентов в матричных вычислениях и отсутствии выделенных для этой цели плотных массивов ALU — таких как тензорное ядро или XMX.
⇡#Трассировка лучей и Mega Geometry
NVIDIA неуклонно увеличивает быстродействие аппаратной трассировки лучей. В этот раз скорость отдельно взятого RT-блока возросла с двух до четырех тестов пересечения луча с треугольником за такт. Количество тестов пересечения с боксами BVH, которые происходят параллельно, по-прежнему остается в тайне, но чипы NVIDIA по меньшей мере в одном аспекте опередили ближайшего конкурента — архитектуру Intel Xe2, которая выполняет 2 теста пересечения луча с треугольником и 18 тестов пересечений с боксами BVH за один такт RT-блока. В свою очередь, RT-блок в составе RDNA3 может определить лишь одно пересечение луча с треугольником за такт либо четыре пересечения с боксом, а прохождение структуры BVH осуществляется программными средствами, на шейдерных ALU.
Кроме того, NVIDIA представила комплекс программных инструментов под названием Mega Geometry, призванный облегчить задачу трассировки лучей в условиях сложной и динамичной геометрии. Современные алгоритмы LOD (Level of Detail) — такие как Nanite в Unreal Engine 5 — плавно варьируют полигональные сетки путем замены мелких кластеров полигонов (около 128) с целью устранить видимые скачки детализации при изменении расстояния от точки обзора до объекта. Однако каждый шаг LOD резко усложняет генерацию BVH, поэтому честная трассировка лучей в комбинации с Nanite и подобными системами не имеет практического смысла, а BVH строится на основе упрощенной прокси-геометрии.
Подход Mega Geometry заключается в том, чтобы алгоритм LOD оперировал сущностями, нативно отраженными в BVH. Для этой цели вводится новый тип примитива BVH — Cluster-level Acceleration Structures. CLAS представляет собой коллекцию локализованных групп треугольников, которая генерируется по требованию (например, когда объект сцены загружен с диска) и может быть кеширована для использования в новых кадрах. Уровень детализации полигональной сетки меняется путем замены CLAS, а в силу того, что CLAS содержит около сотни треугольников, скорость каждой перестройки BVH может быть увеличена на два порядка.
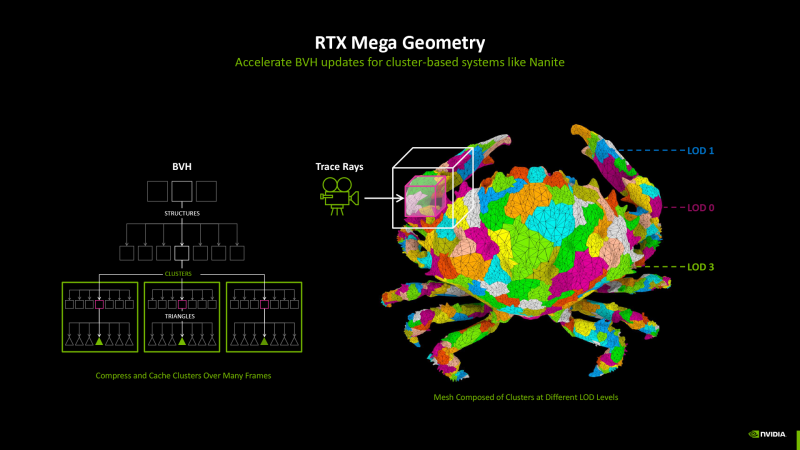
Примитивы CLAS найдут применение не только в играх. В профессиональной 3D-анимации используется алгоритм Subdivision Surfaces, который позволяет формировать криволинейные поверхности путем рекурсивного усложнения полигональной сетки и традиционно выполняется на CPU. Для рейтрейсинга Subdivision Surfaces силами графического процессора необходимо провести тесселяцию кривых в треугольники, что влечет за собой построение объемных BVH каждый кадр. Этот процесс опять-таки может оперировать кешированными кластерами полигонов.
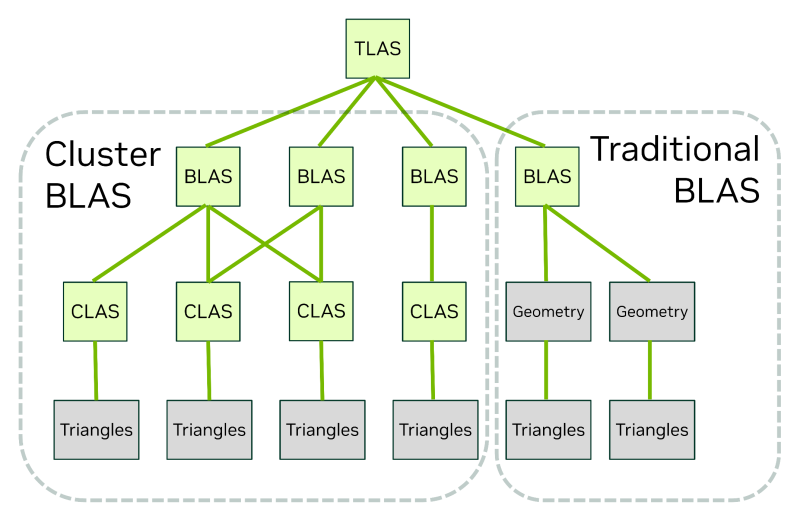
Другое нововведение Mega Geometry позволяет упростить генерацию BVH благодаря новому типу структуры высшего уровня — Partitioned Top-Level Acceleration Structure (PTLAS) — и опирается все на ту же идею: открыть 3D-приложению прямой доступ к BVH, чтобы GPU выполнил определенную часть работы однократно и пользовался результатами в дальнейшем. Так, если игровой движок знает, что определенные объекты игровой сцены какое-то время останутся статичными относительно точки обзора, их можно вынести в собственные разделы BVH, которые не будут перестраиваться без необходимости каждый следующий кадр.
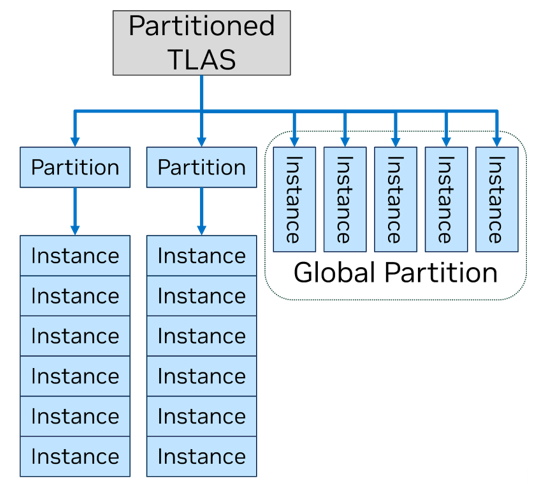
Вызовы Mega Geometry рассчитаны на пакетную обработку, что позволяет целиком разгрузить CPU от таких задач, как выбор LOD, а доступ осуществляется через интерфейсы NVAPI, OptiX и фирменные расширения Vulkan. Это проприетарные API, а о поддержке на уровне стандартной функциональности Direct3D и Vulkan речь пока не идет. Что касается аппаратных требований, то Mega Geometry совместима с любыми RTX-видеокартами, но, разумеется, лучше всего работает на чипах Blackwell, которые имеют специализированную логику (Cluster Engines) для аппаратной компрессии геометрии и BVH. По оценке NVIDIA, расход видеопамяти в таких задачах, как рейтрейсинг с Nanite, удалось сократить на сотни мегабайт.
Наконец, RT-ядро Blackwell способно выполнять проверку пересечения луча с геометрическим примитивом Linear Swept Spheres (LSS), предназначенным для реалистичного моделирования волос, меха, травы и подобных объектов. Фигура LSS образуется путем перемещения сферы по траектории нескольких линейных отрезков с одновременным изменением радиуса и позволяет избавиться от артефактов, свойственных преобладающему методу аппроксимации нитевидных структур — при помощи цепочки полигонов (DOTS, Disjoint Orthogonal Triangle Strips).
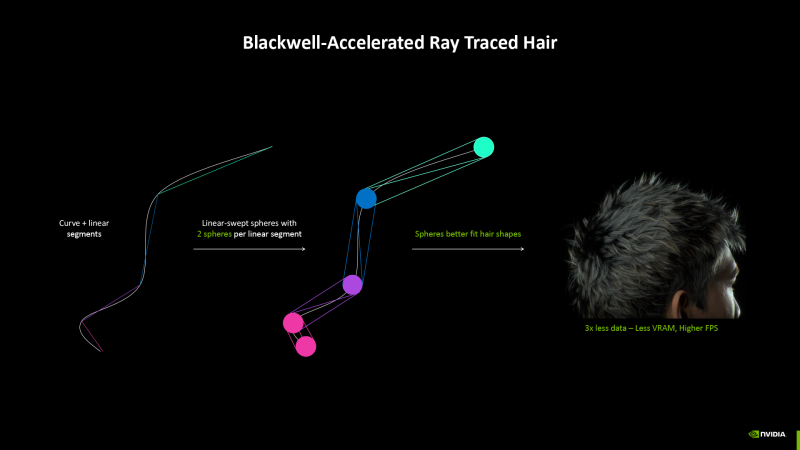
Кроме того, сферы можно использовать и без перемещения (например, для рендеринга частиц). Новый примитив не только позволяет создавать более качественные модели, но и, как утверждает NVIDIA, рендеринг LSS происходит вдвое быстрее, а видеопамяти требуется в пять раз меньше, чем при использовании DOTS.
⇡#Shader Execution Reordering 2.0 и AI Management Processor (AMP)
Одной из немногочисленных инноваций архитектуры Ada Lovelace стала возможность динамически перегруппировывать потоки инструкций (Shader Execution Reordering) для увеличения когерентности доступа к памяти — например, при таких обстоятельствах, как исполнение пиксельных шейдеров на этапе вторичных, отраженных лучей.
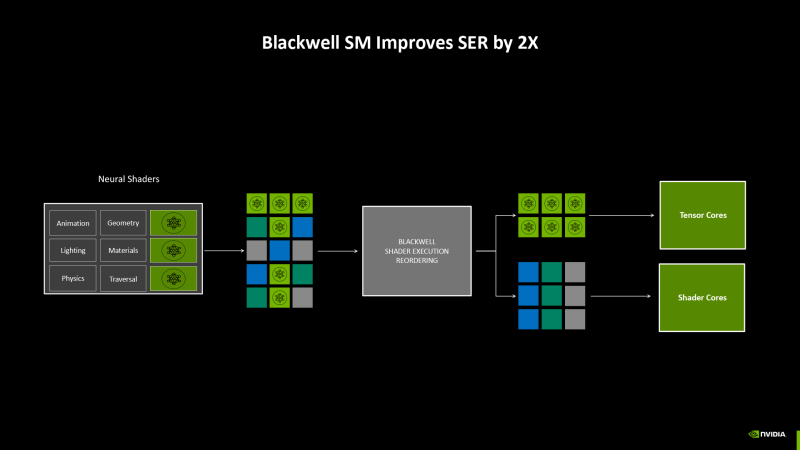
Эффективность логики SER в чипах Blackwell, как утверждает NVIDIA, увеличилась вдвое по оценкам точности перегруппировки и затратам быстродействия на эту операцию. SER также способствует загрузке тензорных ядер, что важно для исполнения новых нейронных шейдеров. Доступ к функциям SER осуществляется эксплицитно через специальный API, который уже освоили некоторые игры с трассировкой путей и пакеты профессионального 3D-рендеринга.
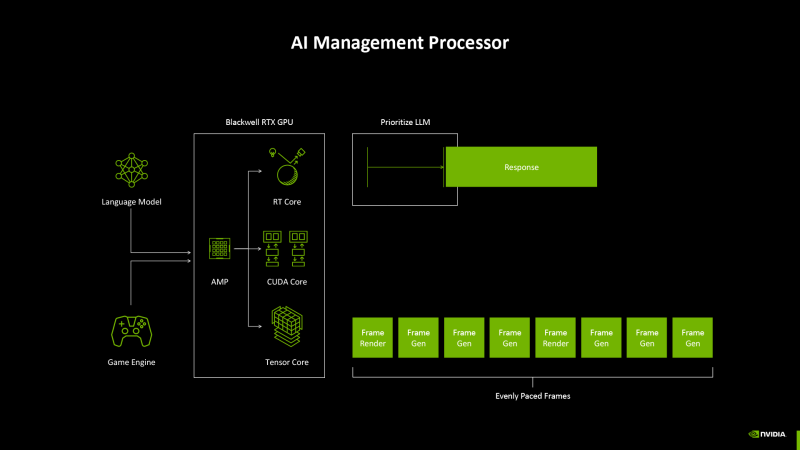
Фронтэнд GPU дополнен полностью программируемым планировщиком контекста на основе отдельного процессора архитектуры RISC-V — AI Management Processor (AMP). Предыдущие итерации «зеленых» чипов, начиная с Turing, уже обладали аппаратным планировщиком, но AMP способен более гибко и, следовательно, эффективно, распределять время GPU в многозадачной среде. Во время игры AMP призван уменьшить задержку ввода за счет выделения приоритетного типа нагрузки — например, нейросетей DLSS.
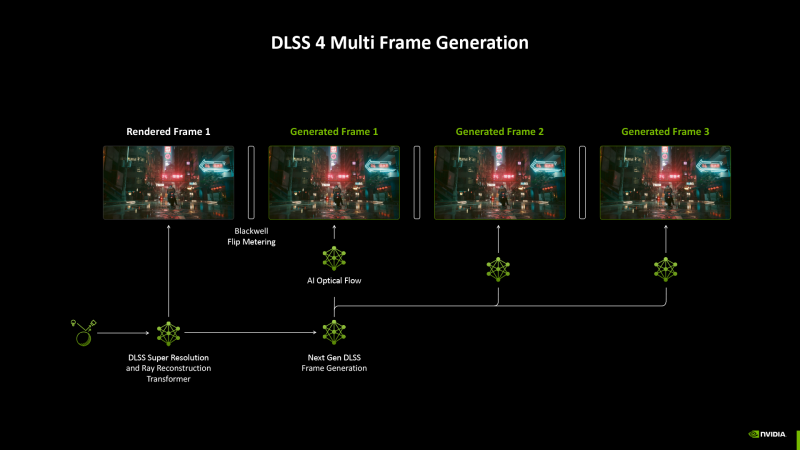
⇡#DLSS 4
Точно так же, как апскейлинг DLSS с функцией генерации кадров для игровых видеокарт GeForce 40, визитной карточкой нового поколения стала генерация при помощи нейросети уже нескольких кадров подряд — вплоть до трех, — которая опирается на особенности чипов Blackwell и, разумеется, не совместима с предыдущими итерациями архитектуры. Сам алгоритм генерации, по оценкам NVIDIA, выполняется на 40 % быстрее и расходует на 30 % меньший объем видеопамяти. Любопытно, что при этом больше не используется аппаратный расчет оптического потока средствами мультимедийного ASIC, который стал (по меньшей мере формальным) препятствием для того, чтобы открыть генерацию кадров ускорителям Ampere — теперь эту функцию выполняет отдельная нейросеть.
Контроль темпа кадров осуществляется аппаратно, на стороне контроллера дисплея, а не центральным процессором. В свою очередь, планировщик AI Management Processor призван регулировать приоритет тех или иных стадий рендеринга с целью уменьшить задержки и минимизировать стохастические просадки кадровой частоты.
Важно заметить, что генерация кадров (тем более множественная, МFG), каким бы качественным ни было изображение, не является полноценной заменой «честного» рендеринга в другом аспекте. Дело в том, что время реакции на ввод зависит от расстояния между кадрами, которые прошли всю логику игрового движка, — иными словами, таким фреймрейтом, который GPU может развить без генерации кадров нейросетью (но, опционально, с масштабированием). А значит MFG сделает движения более плавными, но игра не станет отзывчивой, если исходная кадровая частота лежит ниже комфортной величины (например, 60 FPS).
Генерация кадров, наоборот, отнимает у GPU какую-то долю вычислительных ресурсов и при прочих равных условиях увеличивает время реакции. Поэтому MFG рассчитана на совместную работу с новой версией технологии Reflex. Последняя использует прием Frame Warp, позаимствованный из VR-среды: перед отправкой на монитор кадр меняется в зависимости от последнего перемещения мыши.
Машинное обучение четвертой версии DLSS опирается на модели-трансформеры вместо сверточных нейронных сетей (CNN, Convolutional Neural Networks), которые NVIDIA использовала ранее в силу их сравнительно низкой вычислительной сложности. CNN представляет собой иерархическую структуру, которая (применительно к обработке изображений) осуществляет послойное распознавание визуальных паттернов в направлении снизу вверх — от локализованных групп пикселов к крупным объектам. При этом сама операция свертки является локальной, то есть применяется к изолированному участку изображения, а общий алгоритм всегда работает одинаково на тех или иных данных.
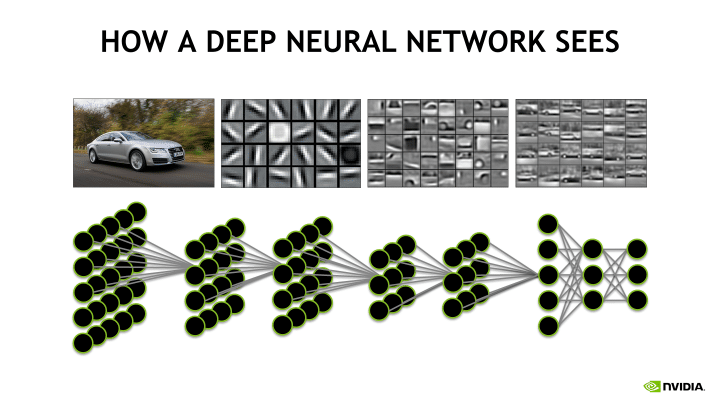
Напротив, ключевым свойством трансформера является так называемое внимание (или самовнимание), которое позволяет целостно рассматривать обрабатываемый материал и направлять вычисления к наиболее важным данным. Благодаря этому трансформеры нашли широкое применение в задачах с выраженным последовательным компонентом — таких, как анализ речи. В контексте DLSS трансформеры более эффективно, нежели CNN, выполняют распознавание крупных паттернов и легче масштабируются, позволяя освоить вдвое больше исходных данных и сильнее загрузить тензорные ядра GPU.
В результате качественно меняется работа всех функций DLSS, включая не только апскейлинг, но также реконструкцию лучей и сглаживание DLAA в нативном разрешении. DLSS 4 позволяет использовать трансформеры и на старом железе, начиная с поколения Turing.
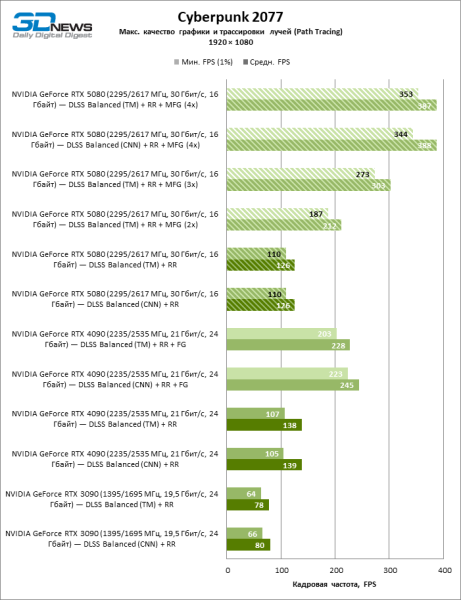
Десктопное приложение NVIDIA способно форсировать MFG (а также другие параметры, включая модель нейросети) в нескольких десятках тайтлов, которые поддерживают DLSS, но еще не обновились до последней версии. В преддверии старта продаж 50-й серии у нас была возможность испытать новые функции апксейлера только в Cyberpunk 2077, который уже получил нативную совместимость с DLSS 4. Как видите, генерация множественных кадров и вправду обеспечивает многократный рост фреймрейта вдобавок к эффекту обычного масштабирования. Что касается модели нейросети, но, к нашему удивлению, трансформеры не вызывают практически существенной потери быстродействия по сравнению со сверточными сетями даже на «зеленом» GPU позапрошлого поколения.
⇡#Нейронные шейдеры
Наконец, еще одна — определенно, не столь провокационная, как MFG, но многообещающая — инициатива заключается в том, чтобы нейросети, работающие на тензорных ядрах, могли непосредственно участвовать в исполнении шейдеров, аппроксимируя результат работы ALU общего назначения. При этом тренировка нейросетей выполняется локально, на самом GPU, иной раз даже в реальном времени. Microsoft уже работает над интерфейсом программирования Cooperative Vectors, который позволяет выполнять умножение матриц с произвольными размерами векторов в любом шейдерном коде, что и требуется нейросетям. Новый API не привязан к железу NVIDIA и в скором будущем должен стать частью Direct3D.
Сценарии применения нейронных шейдеров многообразны, но NVIDIA привела в пример ряд задач, которые получат максимальный прирост быстродействия. Так, нейронные шейдеры способны частично заместить нейросетью математическую модель сложных многослойных материалов. Родственной задачей является моделирование подповерхностного рассеивания света в полупрозрачной среде — такой, как кожа живых существ. В играх для этого до сих пор не задействуют трассировку лучей в связи с высокой вычислительной сложностью, что, опять-таки, призваны исправить нейронные шейдеры.

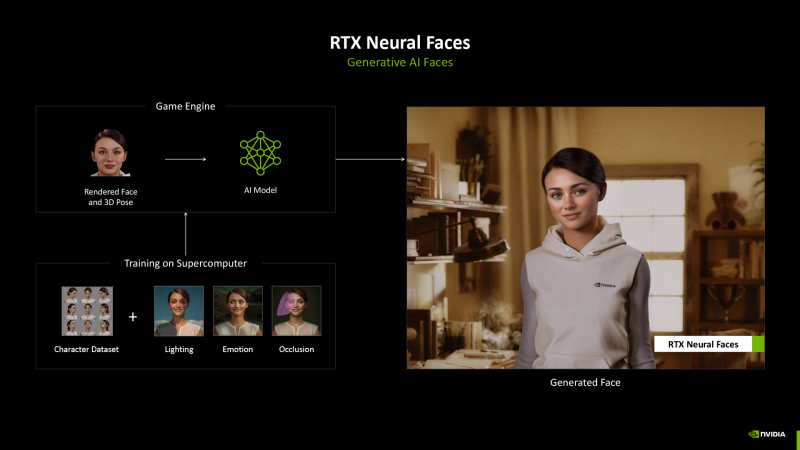
К рендерингу человеческих лиц NVIDIA предлагает привлечь полноценный генеративный ИИ. За основу берется простой растеризованный портрет и пространственные координаты, а нейросеть, заранее тренированная на большом массиве изображений, делает лицо естественным.
Другой разновидностью нейронного шейдера является Neural Radiance Cache (NRC), упрощающий рендеринг глобального освещения с помощью трассировки лучей. Нейросеть NRC непрерывно тренируется в реальном времени, чтобы сформировать аппроксимированную модель вторичного отражения лучей. Как следствие, трассировка ограничивается первичными лучами, а пути лучей следующих порядков направляются в кеш.

Наконец, с помощью нейронных шейдеров возможна более эффективная и качественная компрессия текстур, чем при использовании традиционных методов: NVIDIA продемонстрировала трехкратную экономию объема VRAM. Любопытно, что в таком случае наложение текстур происходит без аппаратной фильтрации (трилинейной или анизотропной). Вместо нее используется стохастическая фильтрация на основе случайной точечной выборки с целью устранить артефакты (лесенки, муар и т.д.).
⇡#Технические характеристики, цены
GeForce RTX 5080 основан на полностью функциональном кристалле GB203, что нетипично для NVIDIA, но оправданно в свете незначительных изменений формулы вычислительных блоков по сравнению с AD103. Если взять за точку отсчета GeForce RTX 4080 и RTX 4080 SUPER, тактовая частота GPU под игровой нагрузкой получила символическую прибавку в 67–112 МГц, а значит, межпоколенческий рост сырой производительности в FP32-вычислениях сводится к мизерным по стандартам графических процессоров 8–15 % TFLOPS.
GeForce RTX 5080 комплектуется 16 Гбайт видеопамяти стандарта GDDR7 с пропускной способностью 30 Гбит/с, которая обеспечивает совокупную ПСП 960 Гбайт/с — на 30–34 % выше по сравнению с двумя разновидностями RTX 4080. Референсная мощность новинки составляет 360 Вт — также заметно больше, чем у RTX 4080 и RTX 4080 SUPER, рассчитанных на энергопотребление 320 Вт.
При таких характеристиках GeForce RTX 5080 представляет собой не что иное, как мягкий апгрейд предшествующих 80-х моделей, но это не помешало NVIDIA сохранить рекомендованную стоимость $999. А значит, пусть часть нововведений архитектуры Blackwell способствует традиционному рендерингу методом грубой силы, потребительская ценность RTX 5080 целиком зиждется на очередной версии DLSS, теперь с функцией генерации множественных кадров.
| Производитель | NVIDIA | ||||
|---|---|---|---|---|---|
| Модель | GeForce RTX 4080 | GeForce RTX 4080 SUPER | GeForce RTX 4090 | GeForce RTX 5080 | GeForce RTX 5090 |
| Графический процессор | |||||
| Название | AD103 | AD103 | AD102 | GB203 | GB202 |
| Архитектура | Ada Lovelace | Blackwell | |||
| Техпроцесс | TSMC 4N | TSMC 4NP | |||
| Число транзисторов, млрд | 45,9 | 45,9 | 76,3 | 45,6 | 92,2 |
| Тактовая частота (Base Clock / Boost Clock), МГц | 2 210/2 505 | 2 205/2 550 | 2 230/2 520 | 2 295/2 617 | 2 017/2 407 |
| Шейдерные ALU (FP32) | 9 728 | 10 240 | 16 384 | 10 752 | 21 760 |
| Блоки наложения текстур (TMU) | 304 | 320 | 512 | 336 | 680 |
| Блоки операций растеризации (ROP) | 112 | 112 | 176 | 168 | 340 |
| Тензорные ядра | 304 | 320 | 512 | 336 | 680 |
| RT-ядра | 76 | 80 | 128 | 84 | 170 |
| Объем кеша L2, Мбайт | 64 | 64 | 96 | 64 | 88 |
| Оперативная память | |||||
| Разрядность шины, бит | 256 | 256 | 384 | 256 | 512 |
| Тип микросхем | GDDR6X SGRAM | GDDR7 SGRAM | |||
| Пропускная способность на контакт, Гбит/с | 22,4 | 23 | 21 | 30 | 28 |
| Общая пропускная способность, Гбайт/с | 717 | 736 | 1 008 | 960 | 1 792 |
| Объем, Гбайт | 16 | 16 | 24 | 16 | 32 |
| Производительность | |||||
| Пиковая производительность FP32, TFLOPS | 49 | 52 | 83 | 56 | 105 |
| Производительность FP64/FP32 | 1/64 | ||||
| Производительность FP16/FP32 | 1/1 | ||||
| Прочее | |||||
| Шина PCI Express | PCI Express 4.0 x16 | PCI Express 5.0 x16 | |||
| Интерфейсы вывода изображения | DisplayPort 1.4a, HDMI 2.1 | DisplayPort 2.1b, HDMI 2.1b | |||
| TDP/TBP, Вт | 320 | 320 | 450 | 360 | 575 |
| Розничная цена (США), $ | 1 199 (рекоменд. в момент выхода) | 999 (рекоменд. в момент выхода) | 1 599 (рекоменд. в момент выхода) | 999 (рекоменд. в момент выхода) | 1 999 (рекоменд. в момент выхода) |
Что касается GeForce RTX 5090, то в данном случае огромный массив вычислительных блоков GB202 урезали на 22 SM (или 2 816 FP32-совместимых шейдерных ALU), а тактовая частота GPU снижена на 113 МГц по сравнению с RTX 4090. Тем не менее разница в теоретическом быстродействии между флагманскими моделями составляет 27 %. Если учесть, что кристалл GB202 приближается к максимальной площади фотошаблона TSMC, NVIDIA выжала почти все из 5-нанометрового техпроцесса, и на лучшие результаты рассчитывать нельзя. GeForce RTX 5090 имеет 32 Гбайт памяти GDDR7, а пропускная способность 28 Гбит/с на 512-битной шине означает громадную ПСП 1 792 Гбайт/с (на 78 % выше, чем у RTX 4090).
Плохие новости в том, что GeForce RTX 5090 расходует вплоть до 575 Вт мощности, а главное, стоит $1 999. Таким образом, две старшие модели 50-й линейки разделяет беспрецедентная дистанция в 86 % теоретического быстродействия и 100 % рекомендованной стоимости — а то и больше в условиях ожидаемого дефицита. Оба устройства поступают в продажу сегодня, поэтому читатели уже могут взглянуть на реальные цены новинок.
⇡#Palit GeForce RTX 5080 GameRock: конструкция
GeForce RTX 5080 в модификации Palit GameRock работает на референсных тактовых частотах и представляет собой огромную видеокарту с точно такими же габаритами (331,9 × 150 × 70,4 мм), как у одноименной версии RTX 5090, что в свете меньшего TBP позволяет рассчитывать на усиленное охлаждение компонентов и низкий уровень шума. Устройство занимает почти четыре слота расширения в корпусе ПК.

Лицевая панель кожуха имеет зеркальную поверхность с гофрированными участками, которая переливается узорами яркой светодиодной подсветки. Паттерн и цвета LED можно регулировать в отдельности или синхронизировать с материнской платой через стандартный ARGB-коннектор, который расположен рядом с входом питания 12V-2×6.

Периметр видеокарты охватывает литая алюминиевая рама с вентиляционными прорезями на длинных сторонах. В бэкплейте, также металлическом, есть уже привычное окно, которое открывает значительную часть радиатора для сквозного прохода воздуха.

Систему охлаждения обслуживают три вентилятора с диаметром крыльчатки 92 мм. При низкой температуре и нагрузке на GPU устройство охлаждается пассивно.
В основе радиатора лежит испарительная камера сложной формы — достаточно крупная, чтобы накрыть кристалл графического процессора и чипы VRAM. В качестве термоинтерфейса между GPU и испарительной камерой используется обычная термопаста. Для силовых каскадов и дросселей VRM предусмотрены отдельные пластинчатые теплосъемники, один из которых напрямую контактирует с тепловыми трубками. Последних здесь, кстати, девять штук.

Хотя бэкплейт сделан из металла, под ним нет ни одной термопрокладки, а значит, пластина не участвует в охлаждении PCB.

В комплект поставки Palit GameRock входит переходник с трех восьмиконтактных разъемов питания на штекер 12V-2×6, кабель синхронизации ARGB, сборная регулируемая опора для жесткого монтажа видеокарты в горизонтальном положении, а еще небольшой тканевый коврик для мыши.

⇡#Palit GeForce RTX 5080 GameRock: печатная плата
Видеокарта собрана на компактной PCB, которая, однако, может похвастаться чрезвычайно мощной системой питания. Регуляцией напряжения и на GPU, и на микросхемах видеопамяти заведуют ШИМ-контроллеры Monolithic Power Systems MP29816 и MP2988. VRM включает в общей сложности 19 фаз, которые укомплектованы силовыми каскадами MPS87993. Их номинальный ток нам в точности не известен, но, предположительно, составляет 90 А.
Маркировка чипов GDDR7 производства Samsung (K4VAF325ZC-SC32) отражает пропускную способность 32 Гбит/с — на 2 Гбит/с выше, чем предусмотрено спецификациями GeForce RTX 5080.


Palit GameRock имеет переключатель версий BIOS. Одна прошивка — «тихая», другая — «производительная». Как выбор прошивки действует на частоты GPU и работу системы охлаждения, мы узнаем в следующей, эмпирической части обзора.
⇡#Тестовый стенд, методика тестирования
| Тестовый стенд | |
|---|---|
| CPU | AMD Ryzen 9 7950X3D (PBO +150 МГц, CU -20) |
| Материнская плата | ASUS ROG Crosshair X670E Hero |
| Оперативная память | G.Skill Trident Z5 Neo RGB (F5-6000J3040G32GX2-TZ5NR), 2 × 32 Гбайт (6200 МТ/с, CL30) |
| ПЗУ | Solidigm P44 Pro, 2 Тбайт |
| Блок питания | Corsair AX1600i, 1600 Вт |
| Система охлаждения CPU | Кастомная СЖО (EK-Quantum Velocity² DDC 4.2 PWM D-RGB + EK-Quantum Surface X280M) |
| Корпус | Открытый стенд |
| Операционная система | Windows 11 Pro |
| ПО для GPU AMD | |
| Все видеокарты | AMD Software Adrenalin Edition 24.12.1 |
| ПО для GPU NVIDIA | |
| GeForce RTX 5080 | NVIDIA GeForce Game Ready Driver 572.02 |
| Остальные видеокарты | NVIDIA GeForce Game Ready Driver 566.36 |
| Игры без трассировки лучей | |||
|---|---|---|---|
| Игра | API | Метод тестирования | Настройки графики |
| Alan Wake 2 | DirectX 12 | OCAT, локация Bright Falls | Макс. качество графики |
| Black Myth: Wukong | DirectX 12 | Встроенный бенчмарк | Макс. качество графики |
| Cyberpunk 2077 | DirectX 12 | Встроенный бенчмарк | Макс. качество графики |
| F1 23 | DirectX 12 | Встроенный бенчмарк, трасса Monaco | Макс. качество графики |
| Hogwarts Legacy | DirectX 12 | OCAT, поездка на тележке в Path to Hogwarts | Макс. качество графики |
| Horizon Zero Dawn Remastered | DirectX 12 | Встроенный бенчмарк | Макс. качество графики |
| Metro Exodus | DirectX 12 | Встроенный бенчмарк | Макс. качество графики; Shading Rate: 100% |
| Red Dead Redemption 2 | Vulkan | Встроенный бенчмарк | Макс. качество графики |
| Returnal | DirectX 12 | Встроенный бенчмарк | Макс. качество графики |
| Total War: WARHAMMER III | DirectX 11 | Встроенный бенчмарк (Mirrors of Madness Benchmark) | Макс. качество графики |
| Игры с трассировкой лучей | ||||||
|---|---|---|---|---|---|---|
| Игра | API | Метод тестирования | Настройки графики | Масштабирование кадров | ||
| AMD | Intel | NVIDIA | ||||
| Alan Wake 2 | DirectX 12 | OCAT, локация Bright Falls | Макс. качество графики и трассировки лучей | FSR Balanced | FSR Balanced | DLSS Balanced + Ray Reconstruction (+ Frame Generation) |
| Black Myth: Wukong | Встроенный бенчмарк | Макс. качество графики и трассировки лучей | FSR Balanced/FSR Balanced + Frame Generation | XeSS Balanced/FSR Balanced + Frame Generation | DLSS Balanced/DLSS Balanced + Frame Generation | |
| Cyberpunk 2077 | Встроенный бенчмарк (OCAT для генерации кадров) | Макс. качество графики и трассировки лучей (Path Tracing) | FSR Balanced/FSR Balanced + Frame Generation | XeSS Balanced/FSR Balanced + Frame Generation | DLSS Balanced (Transformer Model) + Ray Reconstruction (+ Frame Generation) | |
| F1 23 | Встроенный бенчмарк, трасса Monaco | Макс. качество графики и трассировки лучей | FSR Balanced | XeSS Balanced | DLSS Balanced | |
| Hogwarts Legacy | OCAT, поездка на тележке в Path to Hogwarts | Макс. качество графики и трассировки лучей | FSR Balanced | XeSS Balanced | DLSS Balanced (+ Frame Generation) | |
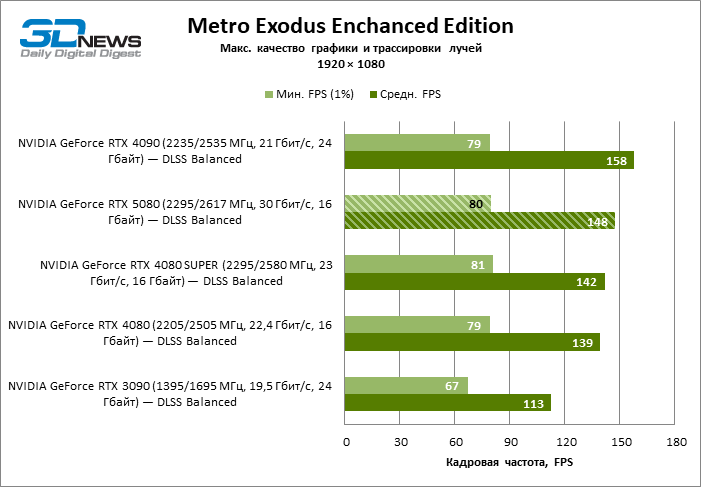
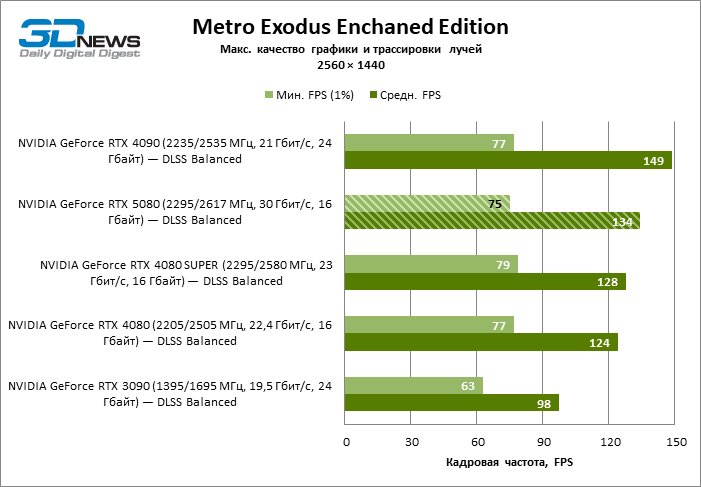
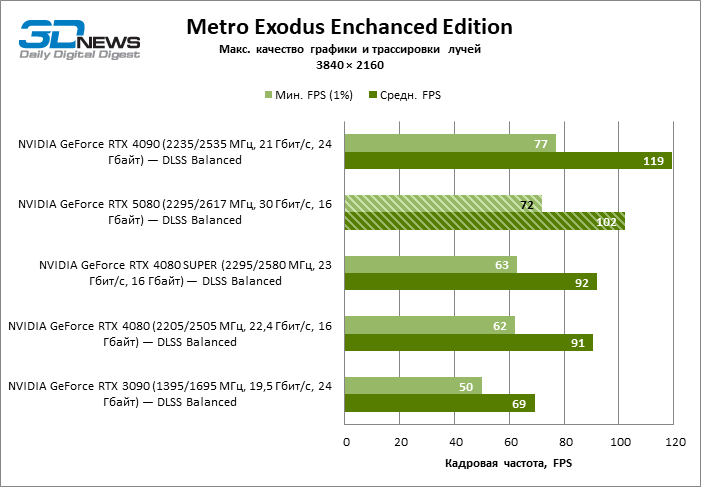
| Metro Exodus Enchanced Edition | Встроенный бенчмарк | Макс. качество графики и трассировки лучей | Н/Д | Н/Д | DLSS Balanced | |
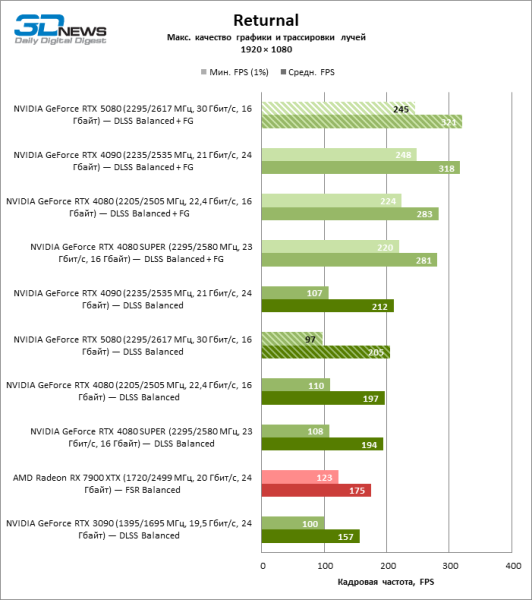
| Returnal | Встроенный бенчмарк (OCAT для генерации кадров) | Макс. качество графики и трассировки лучей | FSR Balanced/FSR Balanced + Frame Generation | XeSS Balanced/FSR Balanced + Frame Generation | DLSS Balanced (+ Frame Generation) | |
В большинстве игр показатели средней и минимальной (мы указываем 1-й процентиль распределения) кадровых частот выводятся из массива времени рендеринга индивидуальных кадров или мгновенного фреймрейта, полученного с помощью встроенного бенчмарка. Исключением являются игры, не имеющие встроенного бенчмарка, и тесты с применением генерации кадров: в этих случаях для захвата межкадровых интервалов мы используем программу OCAT.
| Рабочие приложения | ||
|---|---|---|
| Приложение | Бенчмарк | Настройки |
| Adobe Premiere Pro 25.x | PugetBench for Premiere Pro 1.1.1 (состав тестов по ссылке) | Standard (4K) |
| Blender 4.x | Демо Agent 327 Barbershop с сайта Blender | Рендерер Cycles |
| Blackmagic Design DaVinci Resolve Studio 19.x | PugetBench for DaVinci Resolve 1.1.1 (состав тестов по ссылке) | Standard (4K); H.264/HEVC Encoding Mode: Auto |
| CAD-приложения | SPECviewperf 2020 v3.1 | Разрешение экрана: 3840 × 2160 |
| Декодирование видео (ffmpeg 5.x) | |||
|---|---|---|---|
| Формат | Разрешение | Параметры кодирования | API |
| H.264 (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | High Profile, L4.1 | D3D11VA |
| 3840 × 2160 | High Profile, L5.1 | ||
| HEVC (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | Main Profile, L4.0 | |
| 3840 × 2160 | Main Profile, L5.0 | ||
| 7680 × 4320 | Main Profile, L6.0 | ||
| VP9 (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | Н/Д | |
| 3840 × 2160 | |||
| 7680 × 4320 | |||
| AV1 (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | Main Profile, L4.0 | |
| 3840 × 2160 | Main Profile, L5.0 | ||
| 7680 × 4320 | Main Profile, L6.0 | ||
| Кодирование видео (ffmpeg 5.x) | |||||||
|---|---|---|---|---|---|---|---|
| Формат | Разрешение | Параметры кодирования | API | ||||
| AMD | Intel | NVIDIA | AMD | Intel | NVIDIA | ||
| H.264 (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | -c:v h264_amf -quality speed -coder cabac -refs 1 -b:v 3M | -c:v h264_qsv -preset veryfast -profile:v main -level 4.1 -b:v 3M | -c:v h264_nvenc -preset fast -coder cabac -refs 1 -b:v 3M | AMF | oneVPL | NVENC |
| 3840 × 2160 | -c:v h264_amf -quality speed -coder cabac -refs 1 -b:v 7.5M | -c:v h264_qsv -preset veryfast -profile:v main -level 5.1 -b:v 7.5M | -c:v h264_nvenc -preset fast -coder cabac -refs 1 -b:v 7.5M | ||||
| HEVC (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | -c:v hevc_amf -quality speed -b:v 3M | -c:v hevc_qsv -preset veryfast -tier main -b:v 3M | -c:v hevc_nvenc -preset fast -b:v 3M | |||
| 3840 × 2160 | -c:v hevc_amf -quality speed -b:v 7.5M | -c:v hevc_qsv -preset veryfast -tier main -b:v 7.5M | -c:v hevc_nvenc -preset fast -b:v 7.5M | ||||
| 7680 × 4320 | -c:v hevc_amf -quality speed -b:v 20M | -c:v hevc_qsv -preset veryfast -tier main -b:v 20M | -c:v hevc_nvenc -preset fast -b:v 20M | ||||
| AV1 (YUV 4:2:0, 8 бит/канал) | 1920 × 1080 | -c:v hevc_amf -quality speed -b:v 3M | -c:v av1_qsv -preset veryfast -profile main -b:v 3M | -c:v hevc_nvenc -preset fast -b:v 3M | |||
| 3840 × 2160 | -c:v hevc_amf -quality speed -b:v 7.5M | -c:v av1_qsv -preset veryfast -profile main -b:v 7.5M | -c:v hevc_nvenc -preset fast -b:v 7.5M | ||||
| 7680 × 4320 | -c:v hevc_amf -quality speed -b:v 20M | -c:v av1_qsv -preset veryfast -profile main -b:v 20M | -c:v hevc_nvenc -preset fast -b:v 20M | ||||
Мощность видеокарт регистрируется отдельно от CPU и прочих компонентов ПК с помощью устройства NVIDIA PCAT. В качестве нагрузки для тестов мощности и уровня шума используется игра Cyberpunk 2077 при разрешении 3840 × 2160 и максимальных параметрах качества графики (без трассировки лучей), а также стресс-тест FurMark с наиболее агрессивными настройками (разрешение 3840 × 2160, MSAA 8x). Замеры всех параметров выполняются после прогрева видеокарты, когда температура GPU и тактовые частоты стабилизируются.
⇡#Участники тестирования
В тестировании производительности приняли участие следующие видеокарты:
- NVIDIA GeForce RTX 5080 (2295/2617 МГц, 30 Гбит/с, 16 Гбайт);
- NVIDIA GeForce RTX 4090 (2235/2535 МГц, 21 Гбит/с, 24 Гбайт);
- NVIDIA GeForce RTX 4080 SUPER (2295/2580 МГц, 23 Гбит/с, 16 Гбайт);
- NVIDIA GeForce RTX 4080 (2205/2505 МГц, 22,4 Гбит/с, 16 Гбайт);
- NVIDIA GeForce RTX 3090 (1395/1695 МГц, 19,5 Гбит/с, 24 Гбайт);
- AMD Radeon RX 7900 XTX (1720/2499 МГц, 20 Гбит/с, 24 Гбайт).
Прим. В скобках указаны базовая и boost-частота GPU.
⇡#Тактовые частоты, энергопотребление, температура, уровень шума и разгон
Графический процессор GB203 на плате GeForce RTX 5080 поддерживает тактовую частоту около 2,8 ГГц под игровой нагрузкой — почти такую же, как у AD103 в составе GeForce RTX 4080 или RTX 4080 SUPER. Питающее напряжение GPU также практически не изменилось.
| Рабочие параметры под нагрузкой (Cyberpunk 2077) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Видеокарта | Настройки | Тактовая частота GPU, МГц (шейдерный домен) | Тактовая частота GPU, МГц (front-end) | Напряжение питания GPU, В | Частота вращения вентиляторов, об/мин (% от макс.) | Частота вращения вентиляторов 2, об/мин (% от макс.) | |||
| Средн. | Макс. | Средн. | Макс. | Средн. | Макс. | Средн. | Средн. | ||
| Palit GeForce RTX 5080 GameRock (2295/2617 МГц, 30 Гбит/с, 16 Гбайт) | Silent BIOS | 2790 | 2790 | Н/Д | Н/Д | 1,04 | 1,04 | 1490 (40%) | 1490 (40%) |
| Palit GeForce RTX 5080 GameRock (2295/2617 МГц, 30 Гбит/с, 16 Гбайт) | Performance BIOS | 2790 | 2790 | Н/Д | Н/Д | 1,04 | 1,04 | 1731 (47%) | 1731 (47%) |
| Palit GeForce RTX 5080 GameRock (+500 МГц, 34 Гбит/с, 16 Гбайт) | Performance BIOS | 3247 | 3255 | Н/Д | Н/Д | 1,02 | 1,03 | 2006 (54%) | 2006 (54%) |
| NVIDIA GeForce RTX 3090 FE (1395/1695 МГц, 19,5 Гбит/с, 24 Гбайт) | 1817 | 1830 | Н/Д | Н/Д | 0,90 | 0,91 | 1141 (43%) | 1141 (43%) | |
| NVIDIA GeForce RTX 4080 FE (2205/2505 МГц, 22,4 Гбит/с, 16 Гбайт) | 2775 | 2775 | Н/Д | Н/Д | 1,08 | 1,08 | 1383 (43%) | 1299 (39%) | |
| Palit GeForce RTX 4080 SUPER JetStream OC (2295/2580 МГц, 23 Гбит/с, 16 Гбайт) | 2722 | 2745 | Н/Д | Н/Д | 1,04 | 1,07 | 1473 (39%) | 1473 (39%) | |
| GIGABYTE GeForce RTX 4090 Gaming OC (2235/2535 МГц, 21 Гбит/с, 24 Гбайт) | Silent BIOS | 2730 | 2730 | Н/Д | Н/Д | 1,05 | 1,05 | 1610 (75%) | 1481 (82%) |
| SAPPHIRE NITRO+ Radeon RX 7900 XTX (1720/2499 МГц, 20 Гбит/с, 24 Гбайт) | Secondary BIOS | 2545 | 2585 | 2753 | 2785 | 0,91 | 0,93 | 1412 (34%) | Н/Д |
А вот энергопотребление 80-й модели возросло с 303–311 до 365–372 Вт в Cyberpunk 2077 без трассировки лучей. Полный резерв мощности Palit GameRock и вовсе приближается к отметке 400 Вт.
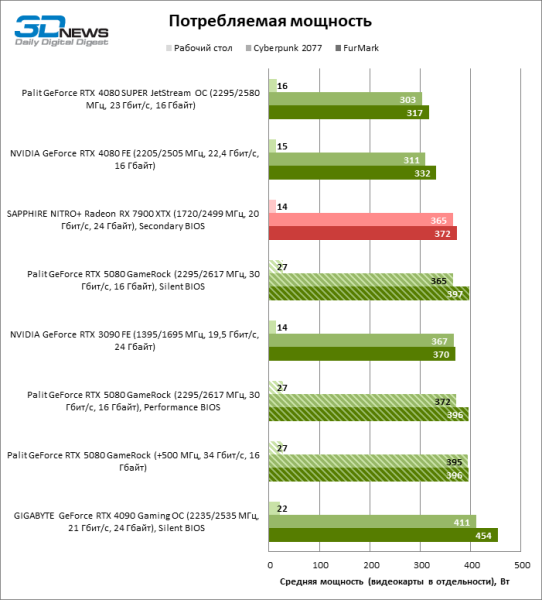
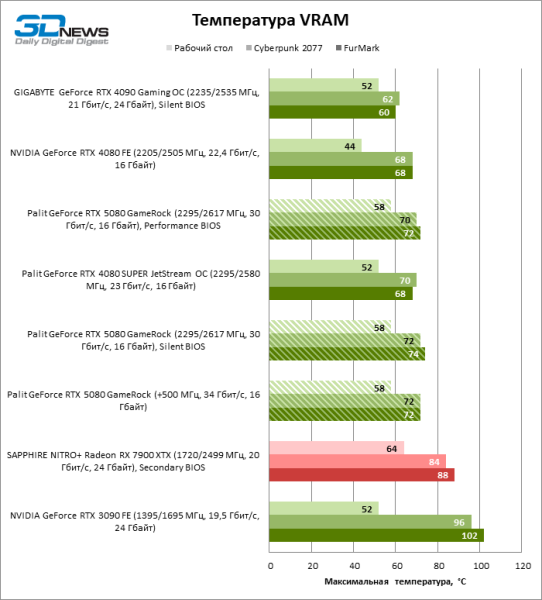
Переключение между «тихой» и «производительной» копиями BIOS не регулирует тактовые частоты и бюджет мощности, но оказывает влияние на скорость вращения вентиляторов. Однако разница в температуре компонентов при использовании разных прошивок не превышает 3 °С. Под стрессовой нагрузкой GPU нагревается от силы до 70, а чипы памяти GDDR7 — 74 °C, что является вполне типичным результатом для современной видеокарты. Заметим, что драйвер чипов Blackwell не выдает информацию о температуре самой горячей зоны кристалла. Вернется ли эта функция в грядущих версиях ПО, пока неизвестно.
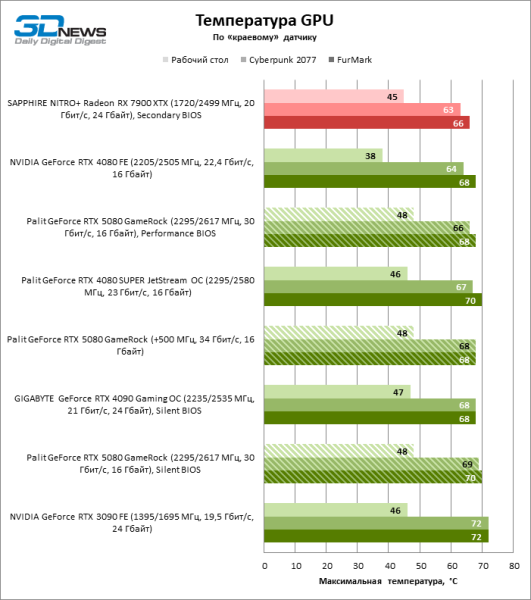
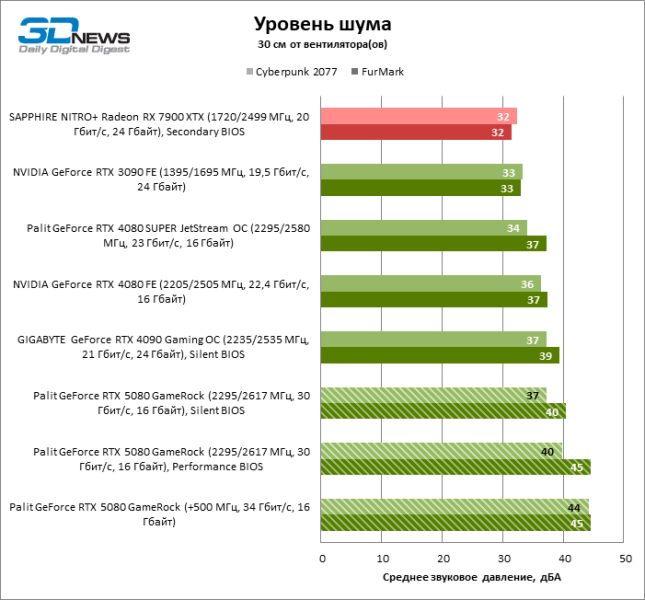
Несмотря на высокое энергопотребление ускорителя, система охлаждения Palit GameRock развивает вполне приемлемый уровень шума вплоть до 37 дБА (на расстоянии 30 см от вентиляторов) под игровой нагрузкой — но при условии, что активна «тихая» прошивка». «Производительный» BIOS увеличивает звуковое давление до 40 дБА при штатных тактовых частотах и хорош только для пользовательского оверклокинга.
GeForce RTX 5080 в модификации Palit GameRock (по крайней мере, без пометки OC) не позволяет увеличить TBP, что, однако, не стало препятствием для удивительно продуктивного разгона. GB203 сохраняет стабильность на частоте 3,25 ГГц (на 457 МГц выше штатного значения) под нагрузкой без трассировки лучей, а питающее напряжение GPU автоматически снизилось на 0,02 В. Столь впечатляющие результаты наверняка связаны с обновленной системой динамической регулировки частоты. Однако постоянные флуктуации в пределах рендеринга одного кадра, за которыми не успевает программа мониторинга, означают и то, что какое-то время GPU не работает на заданной частоте. В свою очередь, чипы видеопамяти нам удалось разогнать с исходной пропускной способности 30 до 34 Гбит/с, и при этом не происходит потери быстродействия вследствие коррекции ошибок.
Разогнанная видеокарта Palit GameRock почти целиком расходует запас мощности около 400 Вт даже в игровом тесте без трассировки лучей. Система охлаждения освоила повышенное тепловыделение без вреда для температуры компонентов, но уровень шума подскочил до 44 дБА.
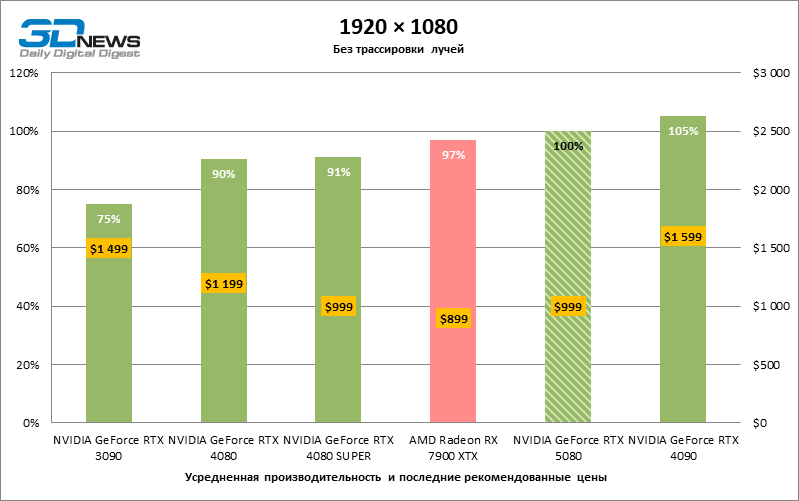
⇡#Игровые тесты (1920 × 1080)
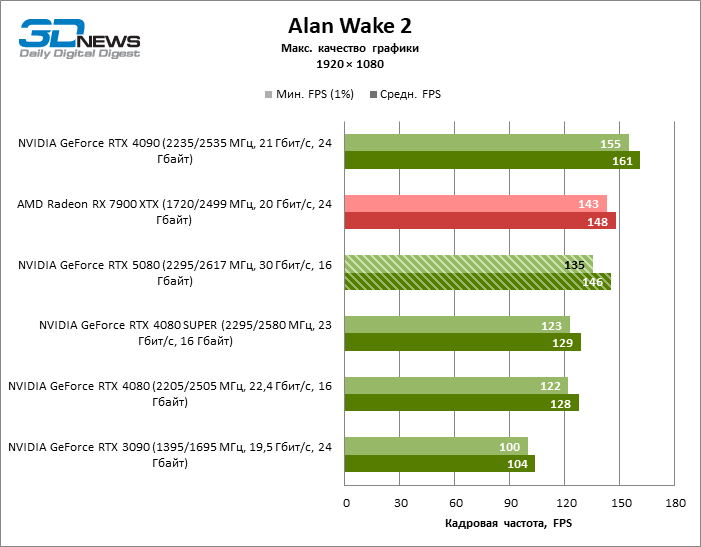
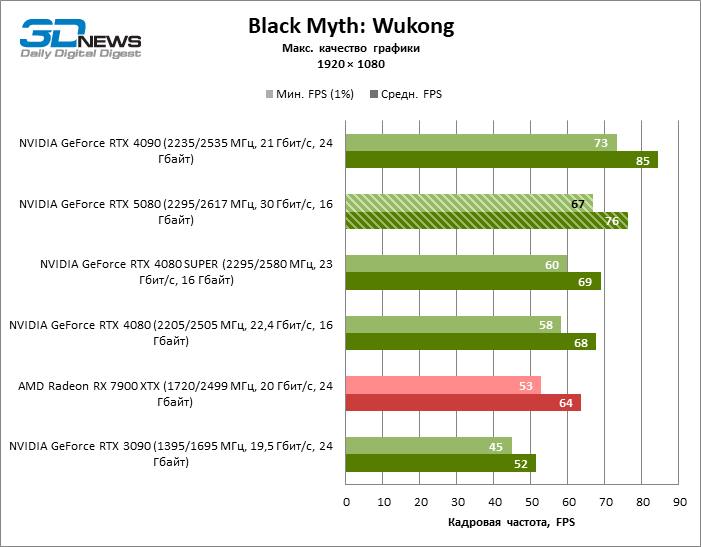
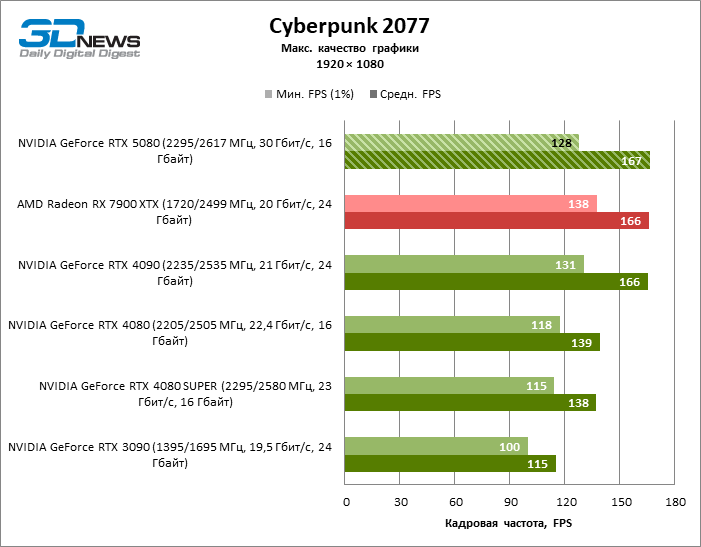
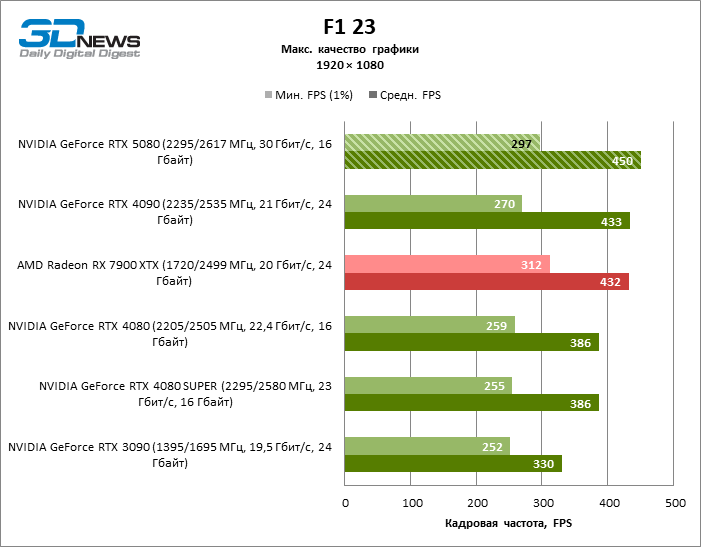
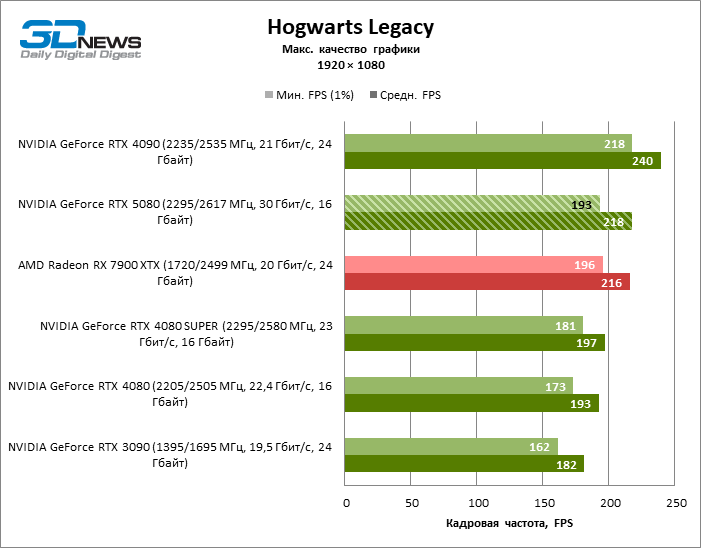
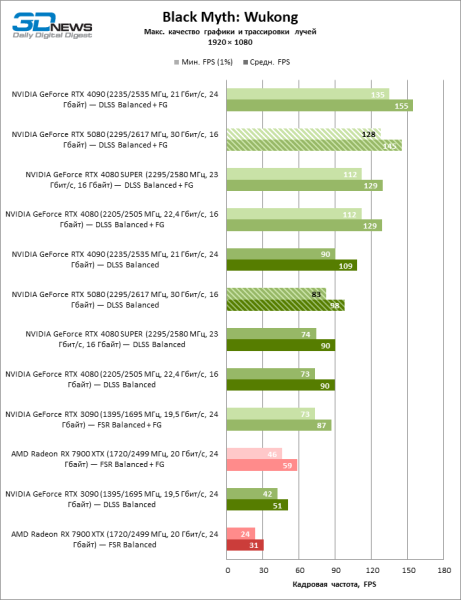
Видеокарты уровня GeForce RTX 5080 обладают избыточной производительностью для растеризованных игр в режиме 1080p и одновременно не могут работать в полную силу при низком разрешении экрана даже на платформах с передовыми центральными процессорами. Как бы то ни было, RTX 5080 развивает кадровую частоту намного выше 100 FPS в подавляющем большинстве тестовых игр. Заметным исключением стала только Black Myth: Wukong, где фреймрейт выше 60 FPS с трудом дается даже самым мощным GPU.
| 1920 × 1080 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 135 / 146 | 100 / 104 | 122 / 128 | 123 / 129 | 155 / 161 | 143 / 148 |
| Black Myth: Wukong | 67 / 76 | 45 / 52 | 58 / 68 | 60 / 69 | 73 / 85 | 53 / 64 |
| Cyberpunk 2077 | 128 / 167 | 100 / 115 | 118 / 139 | 115 / 138 | 131 / 166 | 138 / 166 |
| F1 23 | 297 / 450 | 252 / 330 | 259 / 386 | 255 / 386 | 270 / 433 | 312 / 432 |
| Hogwarts Legacy | 193 / 218 | 162 / 182 | 173 / 193 | 181 / 197 | 218 / 240 | 196 / 216 |
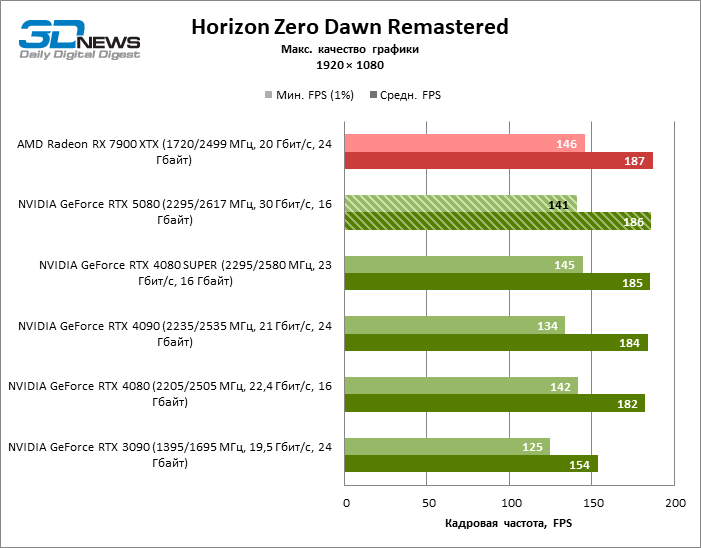
| Horizon Zero Dawn Remastered | 141 / 186 | 125 / 154 | 142 / 182 | 145 / 185 | 134 / 184 | 146 / 187 |
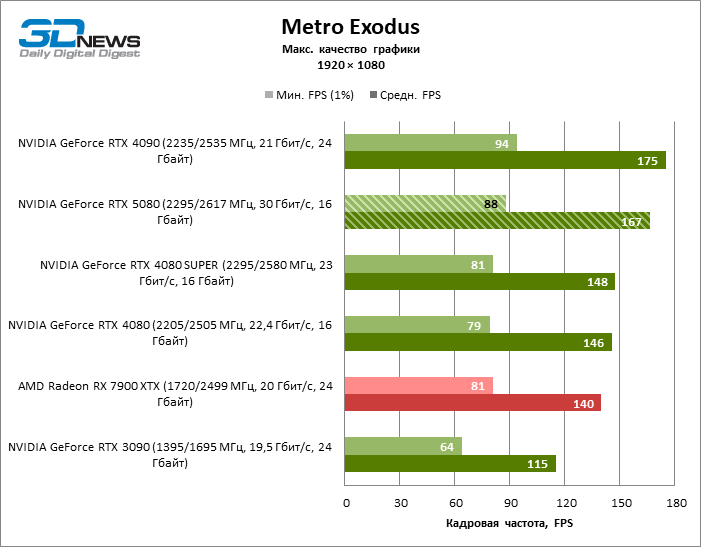
| Metro Exodus | 88 / 167 | 64 / 115 | 79 / 146 | 81 / 148 | 94 / 175 | 81 / 140 |
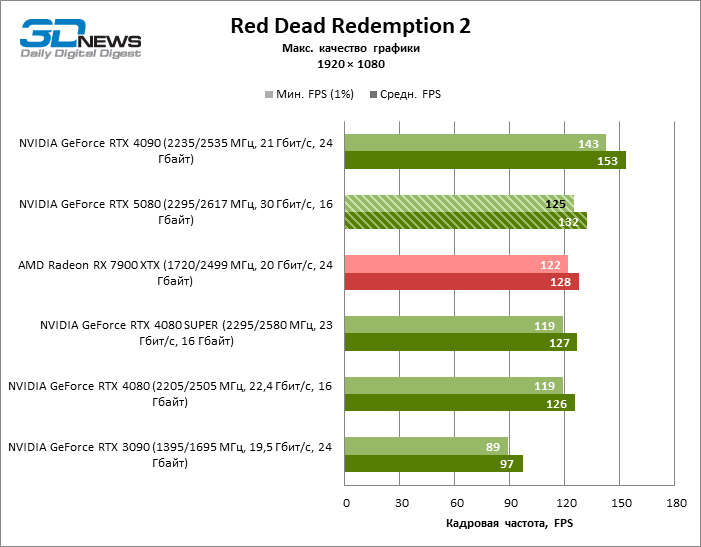
| Red Dead Redemption 2 | 125 / 132 | 89 / 97 | 119 / 126 | 119 / 127 | 143 / 153 | 122 / 128 |
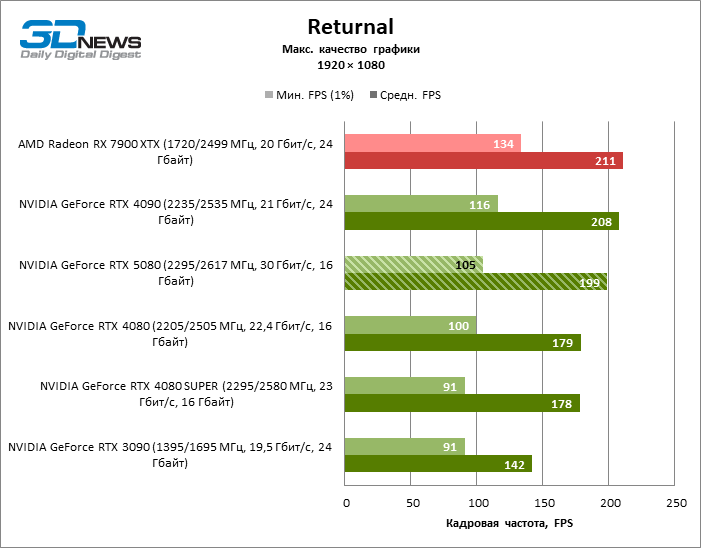
| Returnal | 105 / 199 | 91 / 142 | 100 / 179 | 91 / 178 | 116 / 208 | 134 / 211 |
| Total War: WARHAMMER III | 83 / 105 | 73 / 92 | 86 / 103 | 88 / 105 | 83 / 105 | 85 / 107 |
| Макс. | −12% | −2% | 0% | +16% | +6% | |
| Средн. | −25% | −10% | −9% | +5% | −3% | |
| Мин. | −32% | −17% | −17% | −4% | −16% | |
В силу неоптимальных тестовых условий средние результаты участников тестирования распределены в очень узком диапазоне. Однако уже можно говорить о некоторых тенденциях. Так, по сравнению с GeForce RTX 4080 или RTX 4080 SUPER быстродействие 80-й модели увеличилось лишь на 10–11 %. Radeon RX 7900 XTX почти не уступает новинке, а GeForce RTX 5090 имеет столь же незначительное преимущество. GeForce RTX 5080 выглядит как заметный апгрейд только на фоне GeForce RTX 3090, обеспечивая рост усредненного фреймрейта на 33 %.
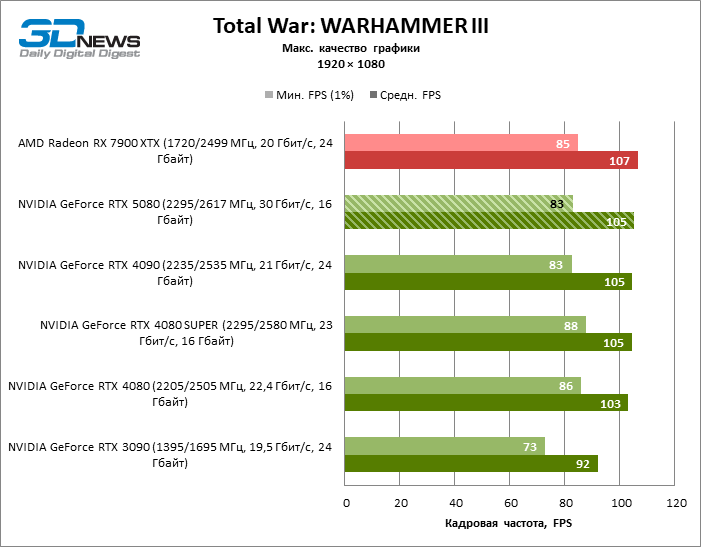
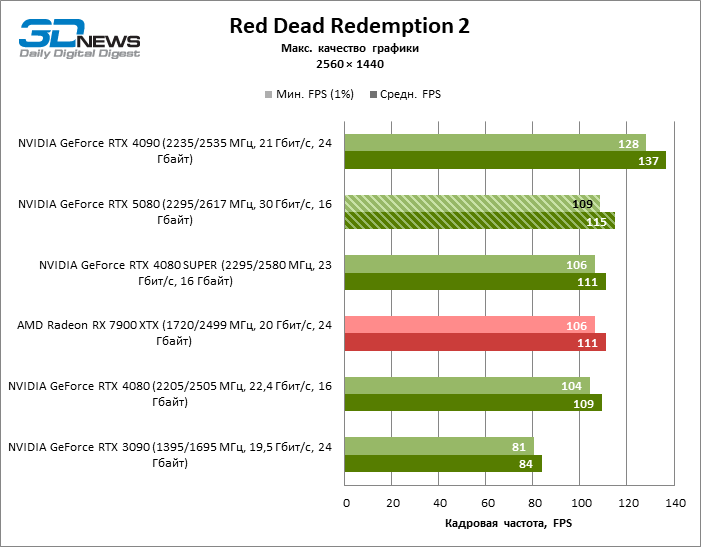
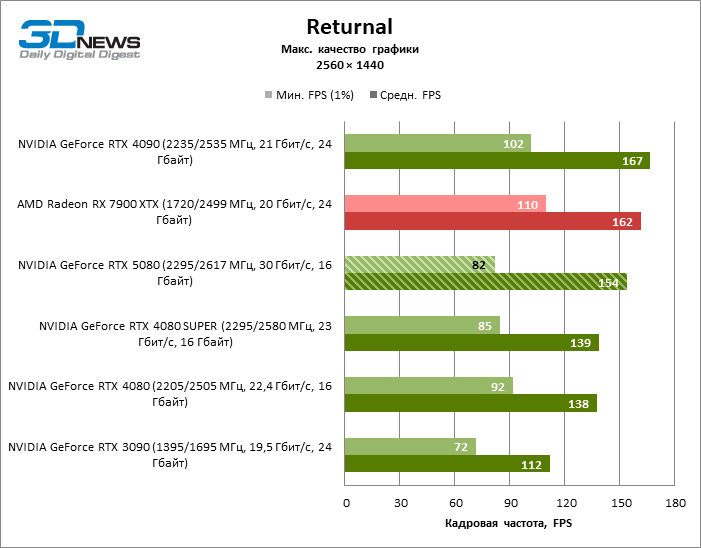
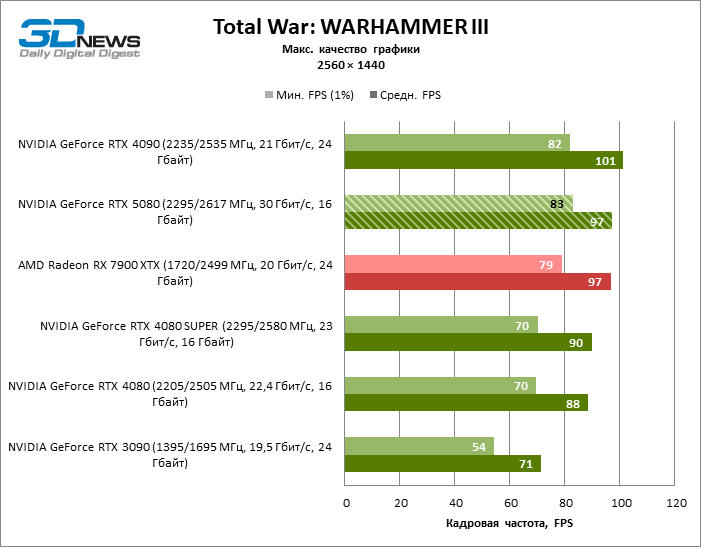
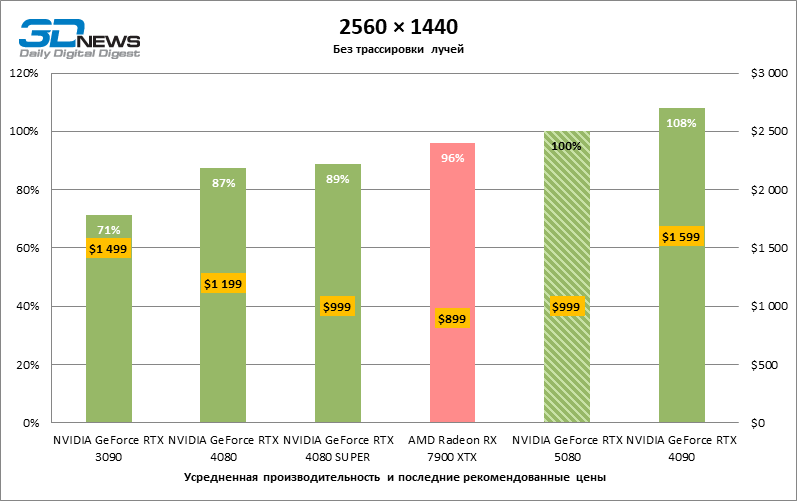
⇡#Игровые тесты (2560 × 1440)
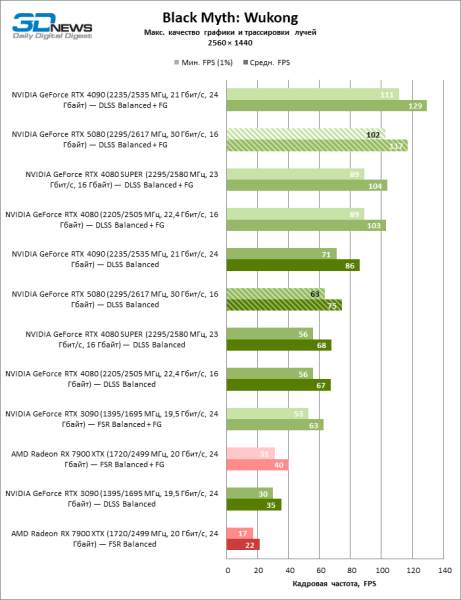
Общие выводы о результатах GeForce RTX 5080 в режиме 1080p можно распространить и на игры без рейтрейсинга при разрешении 1440p. Ни один из тестовых тайтлов не в состоянии так загрузить новый ускоритель NVIDIA, чтобы средний фреймрейт опустился ниже 60, а чаще и 100 FPS. Однако остается все меньше сомнений в том, что прорывного быстродействия от RTX 5080 ждать не стоит.
| 2560 × 1440 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 104 / 109 | 70 / 76 | 90 / 95 | 92 / 97 | 117 / 123 | 103 / 107 |
| Black Myth: Wukong | 54 / 61 | 35 / 40 | 46 / 52 | 47 / 54 | 60 / 68 | 43 / 50 |
| Cyberpunk 2077 | 89 / 102 | 58 / 69 | 67 / 80 | 67 / 80 | 80 / 97 | 90 / 103 |
| F1 23 | 261 / 351 | 202 / 245 | 235 / 291 | 227 / 295 | 247 / 368 | 270 / 343 |
| Hogwarts Legacy | 141 / 165 | 109 / 128 | 124 / 139 | 125 / 142 | 166 / 185 | 141 / 160 |
| Horizon Zero Dawn Remastered | 124 / 163 | 104 / 126 | 128 / 156 | 127 / 158 | 122 / 169 | 130 / 160 |
| Metro Exodus | 85 / 145 | 55 / 97 | 69 / 124 | 75 / 126 | 85 / 158 | 72 / 120 |
| Red Dead Redemption 2 | 109 / 115 | 81 / 84 | 104 / 109 | 106 / 111 | 128 / 137 | 106 / 111 |
| Returnal | 82 / 154 | 72 / 112 | 92 / 138 | 85 / 139 | 102 / 167 | 110 / 162 |
| Total War: WARHAMMER III | 83 / 97 | 54 / 71 | 70 / 88 | 70 / 90 | 82 / 101 | 79 / 97 |
| Макс. | −22% | −4% | −3% | +19% | +5% | |
| Средн. | −29% | −13% | −11% | +8% | −4% | |
| Мин. | −34% | −22% | −22% | −5% | −18% | |
Герой обзора оказался на 40 % быстрее вице-флагманской модели позапрошлого поколения, но дистанция между 80-ми моделями 50-й и 40-й линейки сводится к 12–14 % кадровой частоты. Radeon RX 7900 XTX отстает от RTX 5080 на 4 % FPS, а GeForce RTX 4090 ушел вперед на расстояние в 8 %.
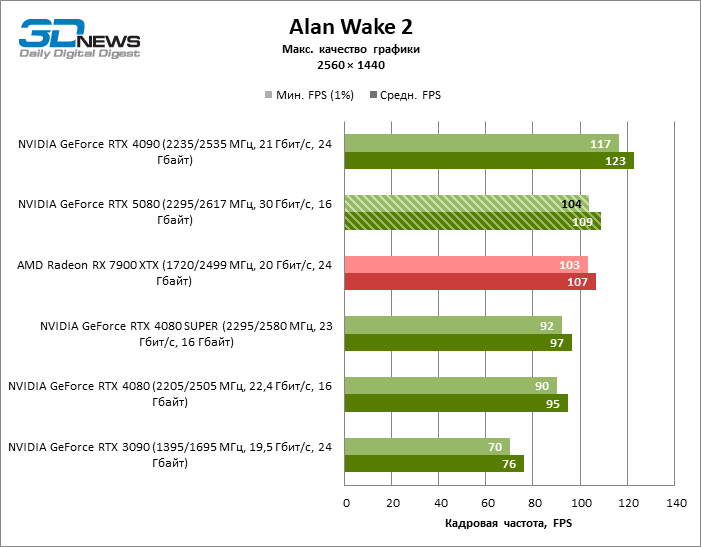
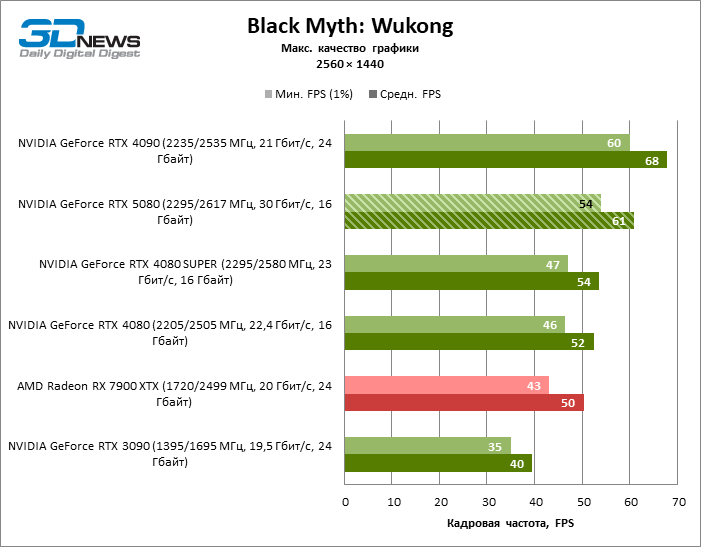
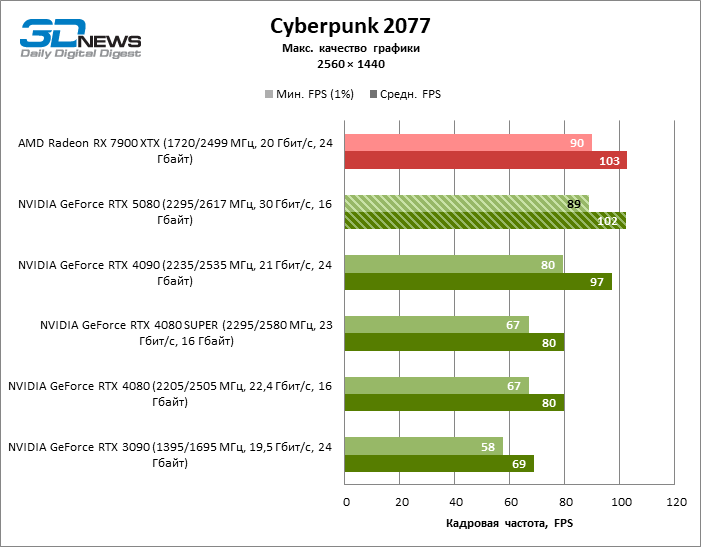
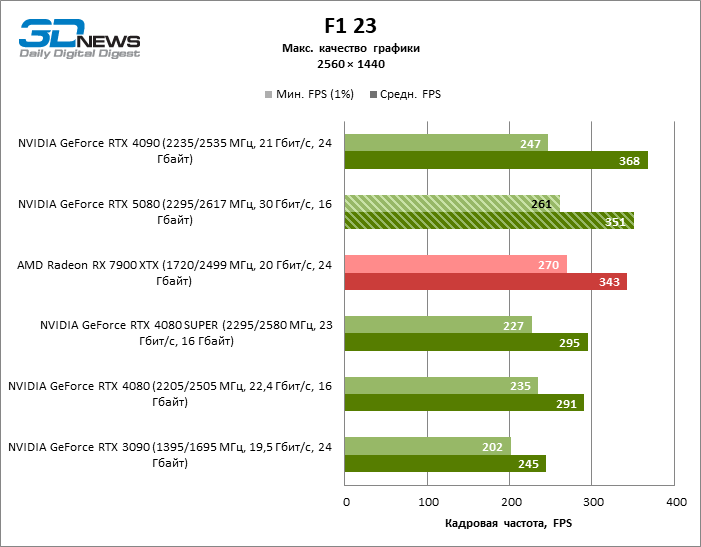
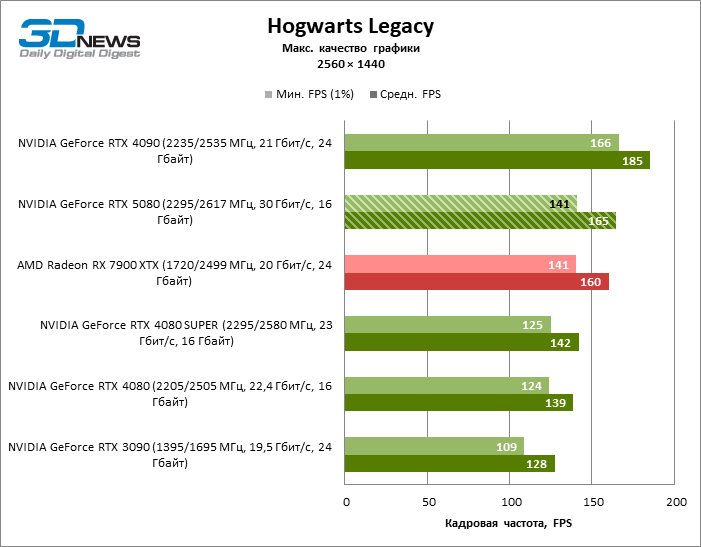
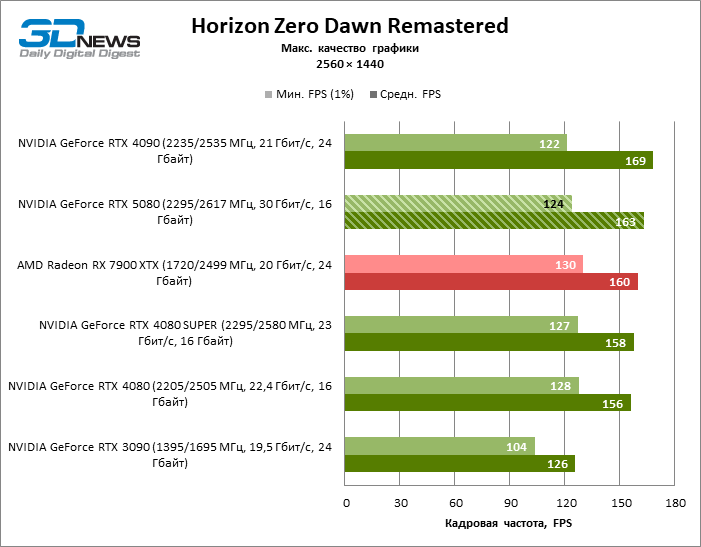
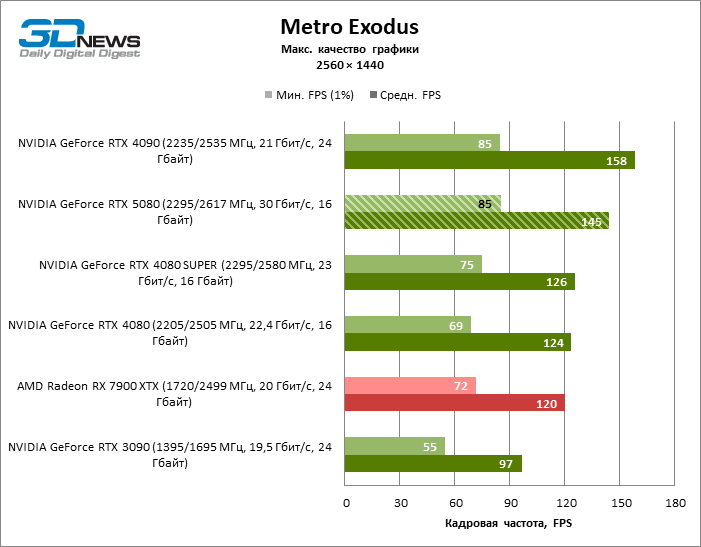
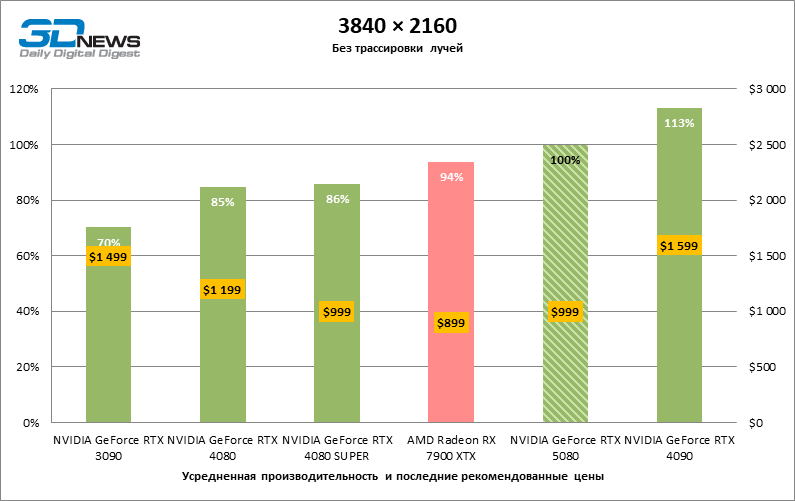
⇡#Игровые тесты (3840 × 2160)
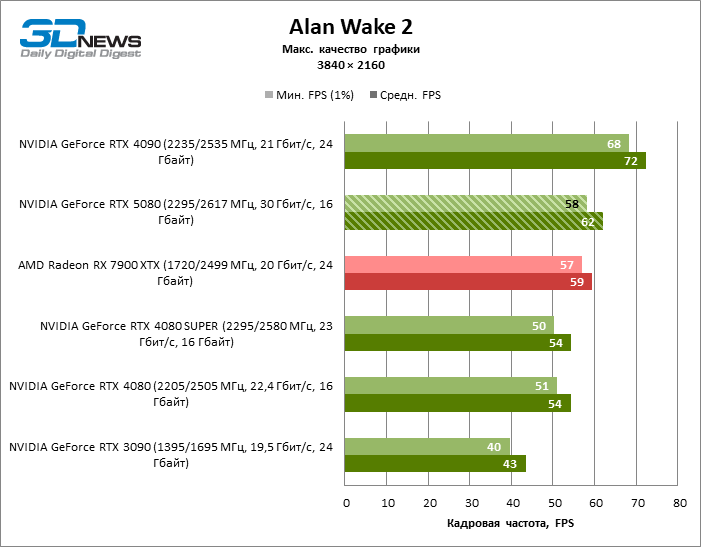
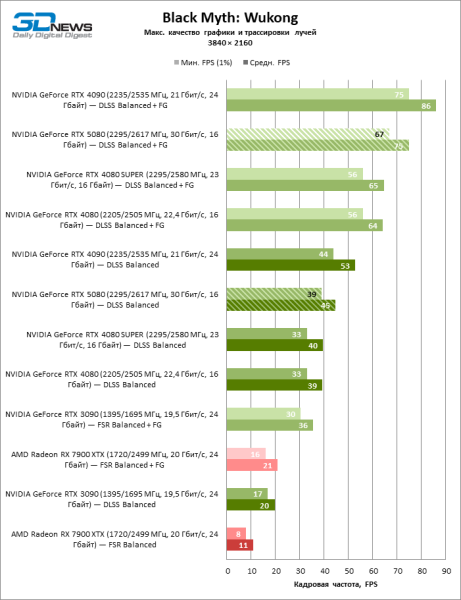
GeForce RTX 5080 позиционируется как ускоритель для игр на 4К-экране. И он действительно развивает фреймрейт от 60 FPS в большинстве тайтлов (а в некоторых по-прежнему за сотню). Ожидаемыми исключениями стали Black Myth: Wukong и Cyberpunk 2077.
| 3840 × 2160 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 58 / 62 | 40 / 43 | 51 / 54 | 50 / 54 | 68 / 72 | 57 / 59 |
| Black Myth: Wukong | 33 / 36 | 21 / 24 | 28 / 31 | 28 / 32 | 38 / 43 | 27 / 31 |
| Cyberpunk 2077 | 39 / 46 | 26 / 32 | 29 / 35 | 28 / 36 | 34 / 44 | 38 / 44 |
| F1 23 | 177 / 210 | 121 / 138 | 145 / 166 | 148 / 169 | 191 / 228 | 172 / 202 |
| Hogwarts Legacy | 90 / 102 | 67 / 77 | 70 / 81 | 75 / 83 | 101 / 113 | 81 / 95 |
| Horizon Zero Dawn Remastered | 86 / 103 | 68 / 80 | 83 / 98 | 85 / 100 | 103 / 127 | 87 / 102 |
| Metro Exodus | 67 / 103 | 44 / 67 | 55 / 85 | 56 / 86 | 73 / 115 | 52 / 86 |
| Red Dead Redemption 2 | 78 / 83 | 54 / 59 | 70 / 76 | 68 / 76 | 94 / 100 | 78 / 81 |
| Returnal | 68 / 99 | 49 / 72 | 62 / 86 | 57 / 86 | 77 / 111 | 68 / 98 |
| Total War: WARHAMMER III | 47 / 63 | 32 / 43 | 39 / 52 | 40 / 53 | 56 / 72 | 42 / 59 |
| Макс. | −22% | −5% | −3% | +23% | −1% | |
| Средн. | −30% | −15% | −14% | +13% | −6% | |
| Мин. | −35% | −24% | −22% | −4% | −17% | |
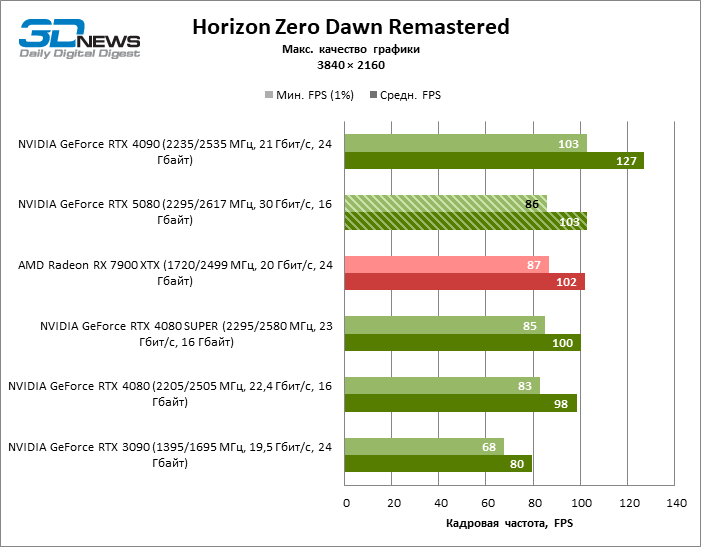
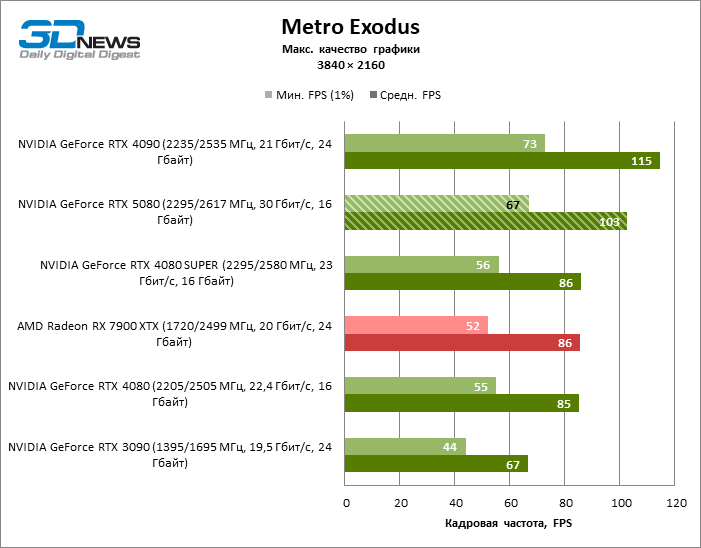
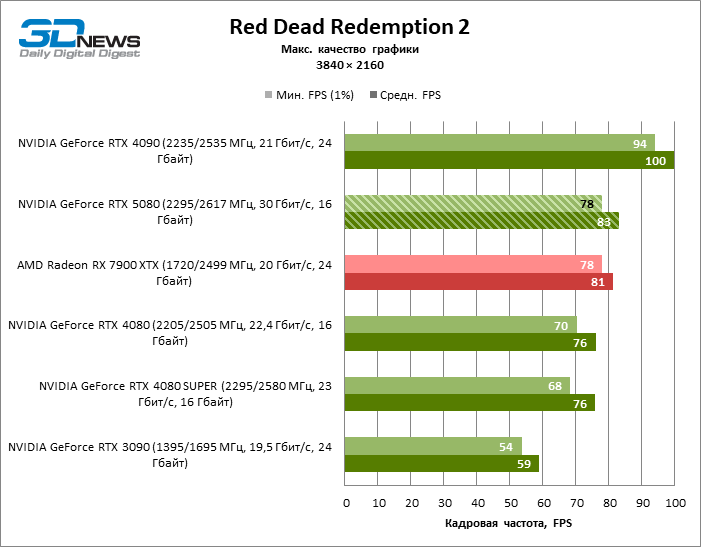
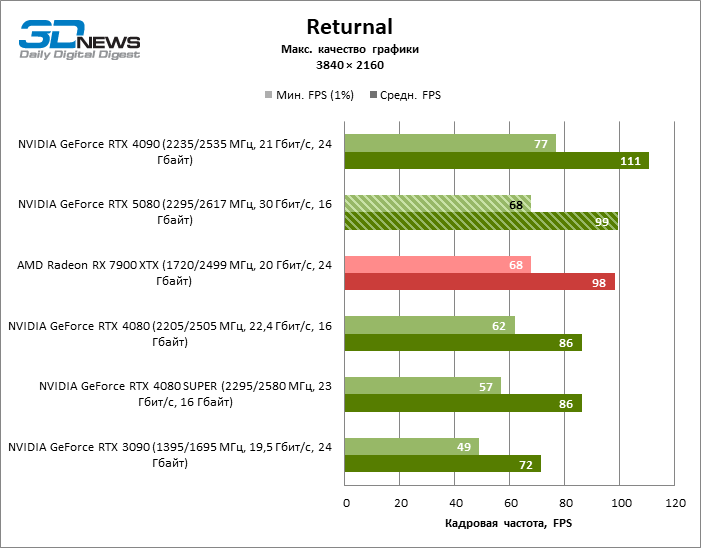
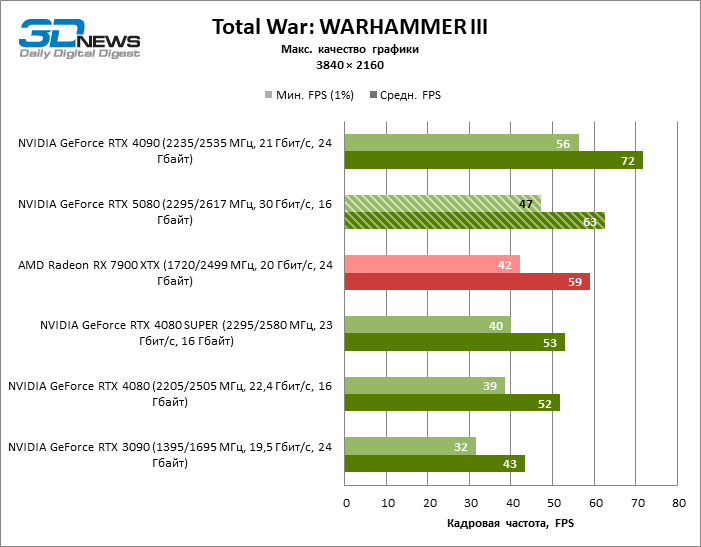
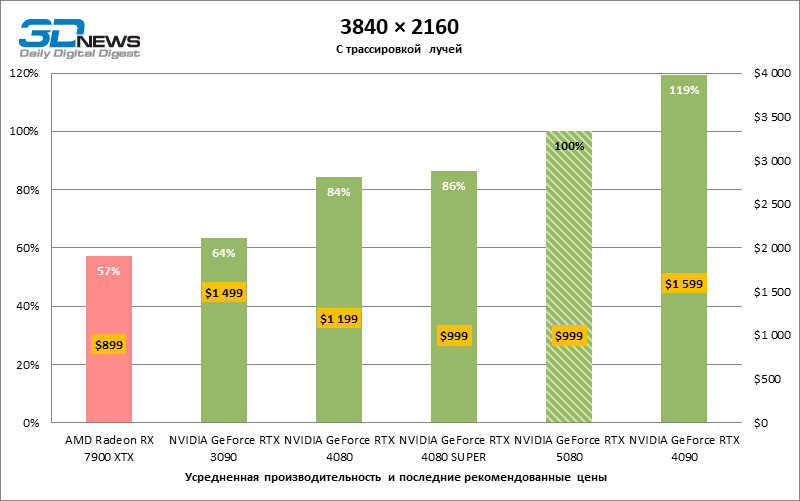
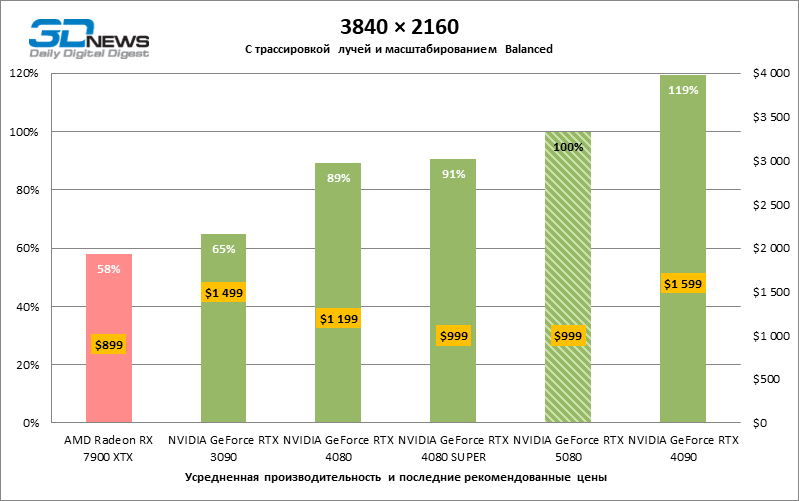
Разница между сравниваемыми устройствами достигла максимальных значений, возможных без привлечения трассировки лучей, но GeForce RTX 5080 по-прежнему не выглядит как устройство следующего поколения. По сравнению с GeForce RTX 3090 быстродействие RTX 5080 оказалось на 43 % выше, но, если взять за точку отсчета GeForce RTX 4080 и RTX 4080 SUPER, прирост сводится к 16–18 % FPS. В свою очередь, преимущество GeForce RTX 4090 увеличилось до 13% среднего фреймрейта. Наконец, главным спойлером GeForce RTX 5080 в растеризации остается Radeon RX 7900 XTX, который уступил новинке лишь 6 % FPS.
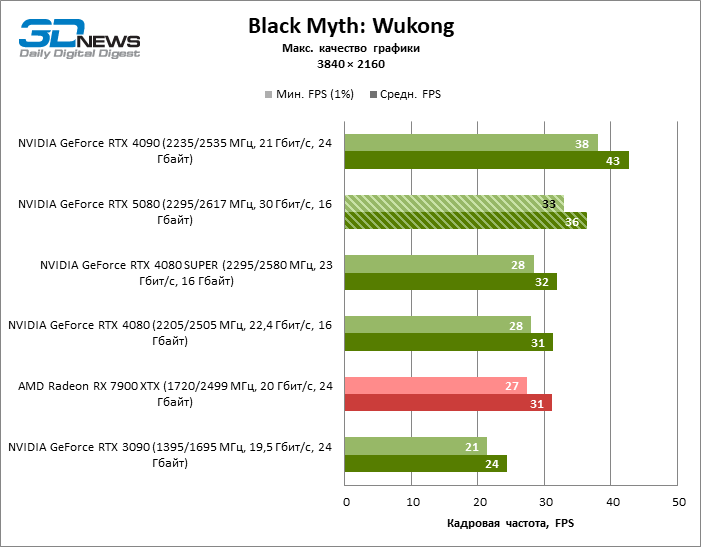
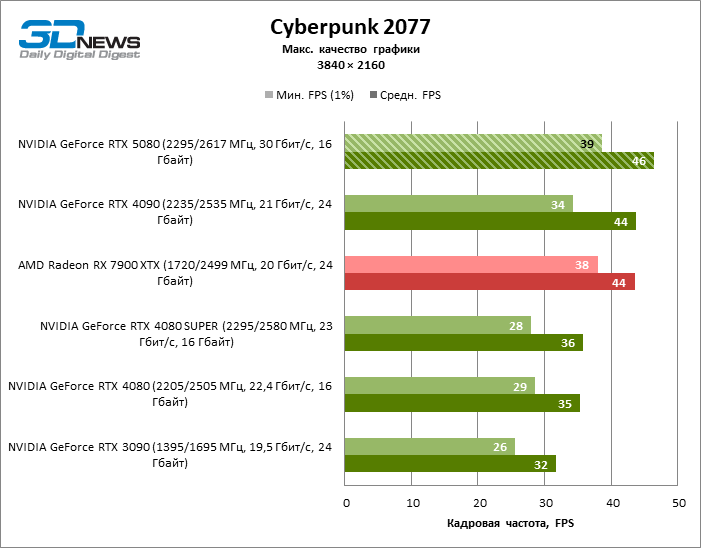
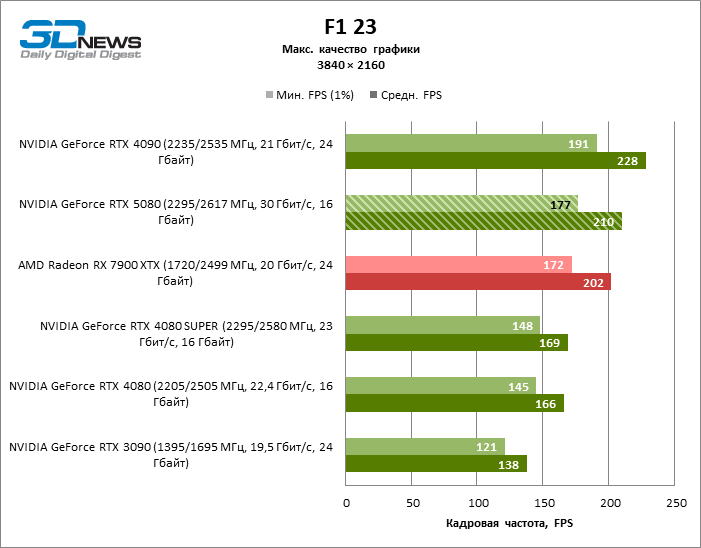
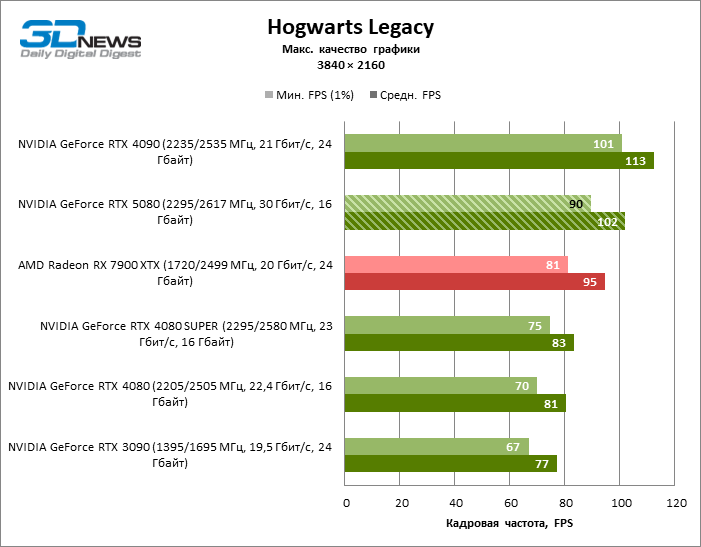
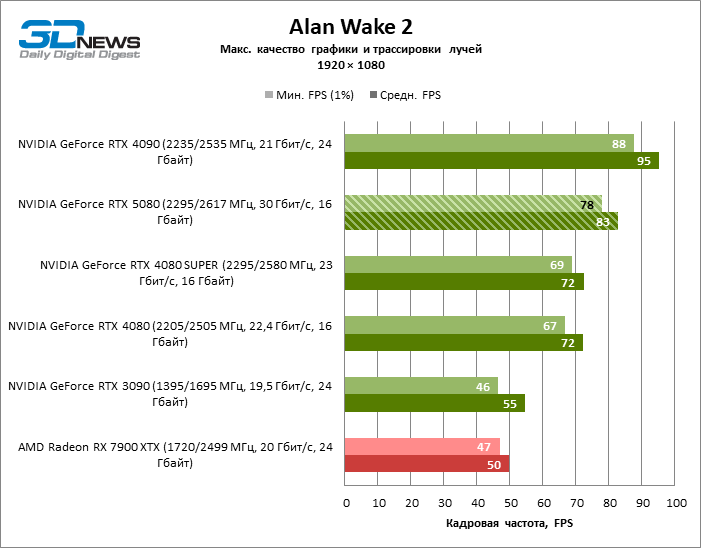
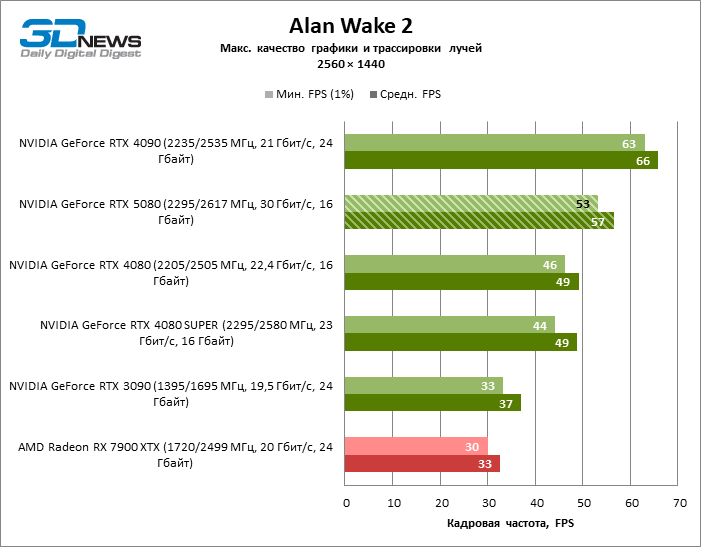
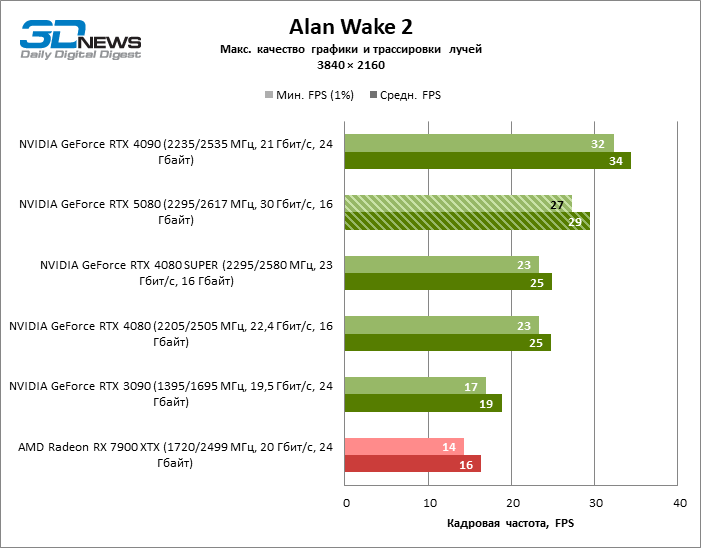
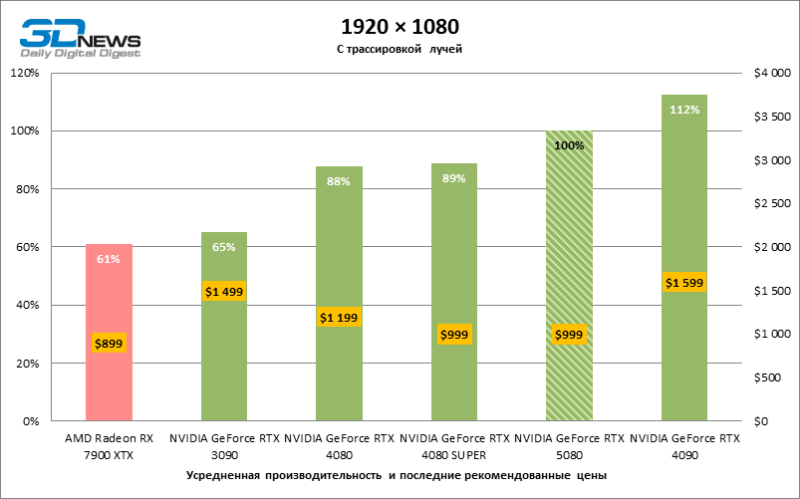
⇡#Игровые тесты с трассировкой лучей
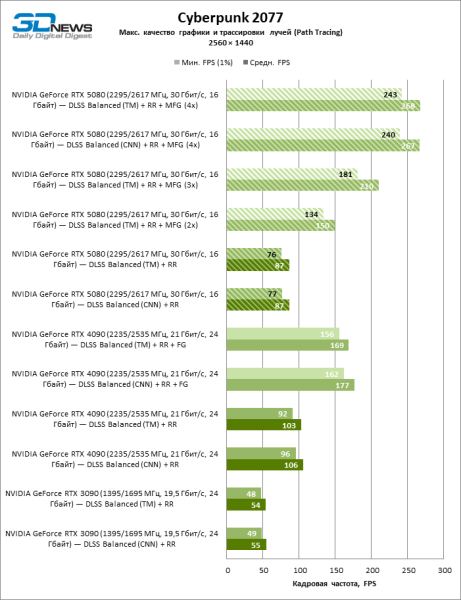
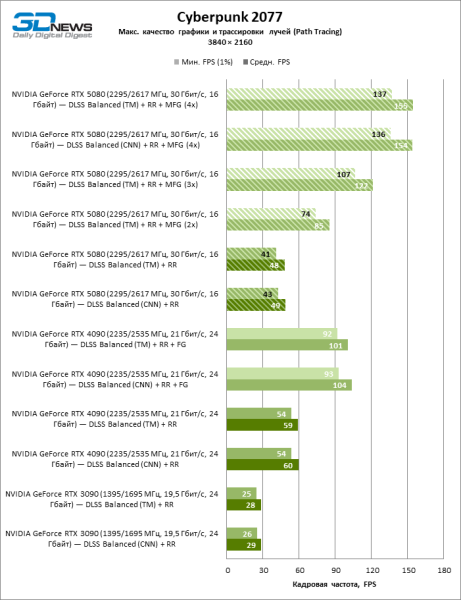
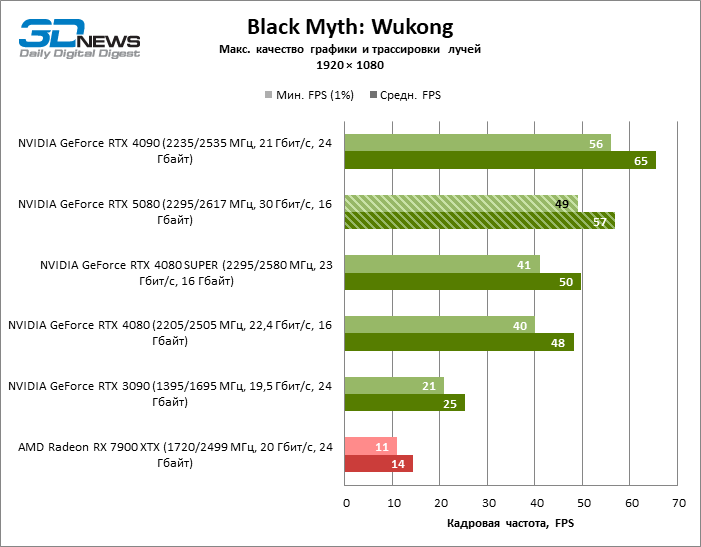
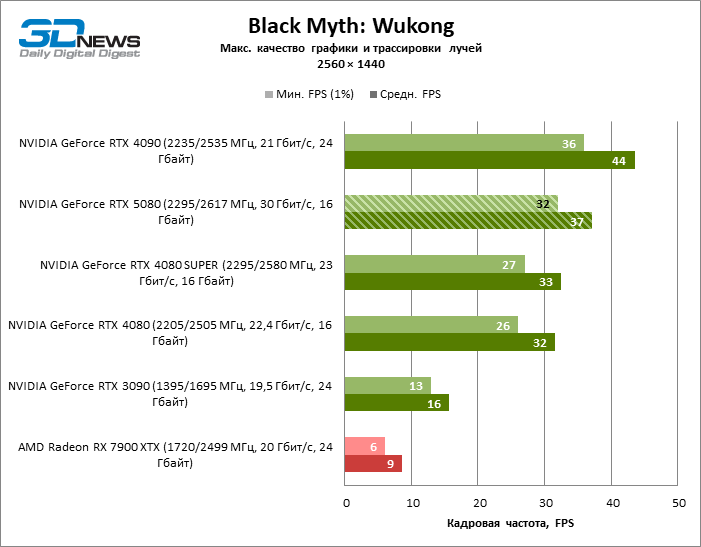
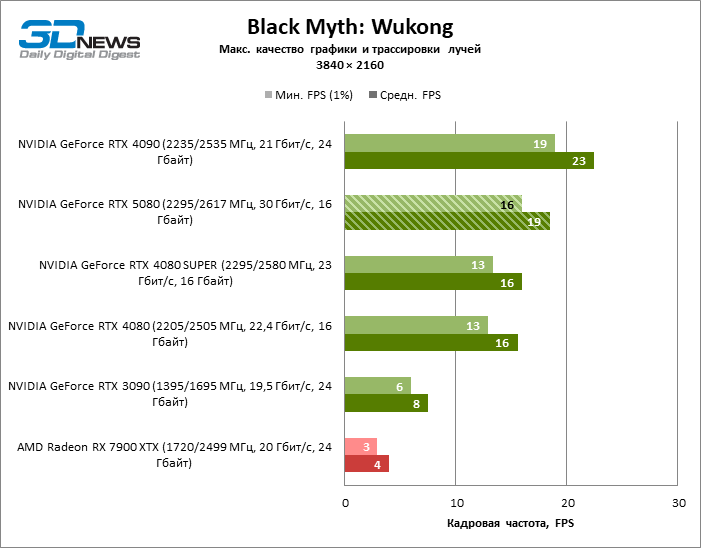
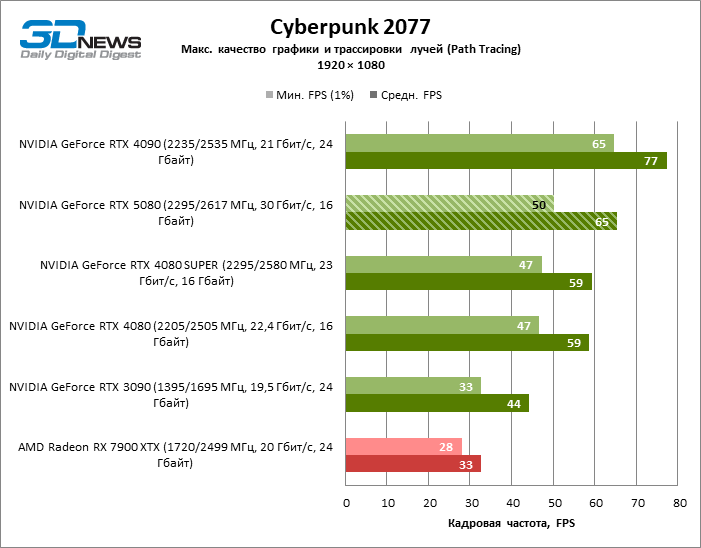
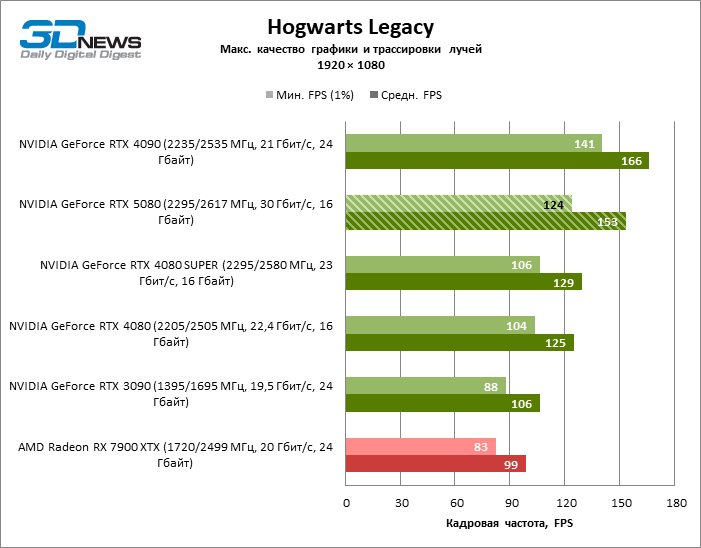
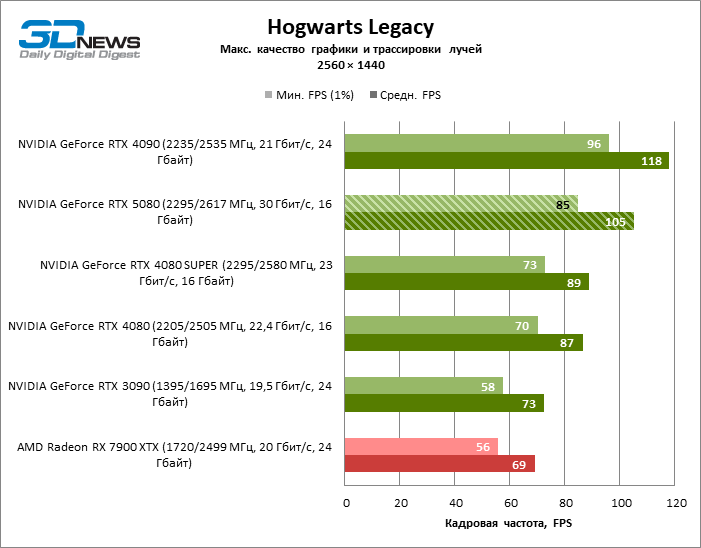
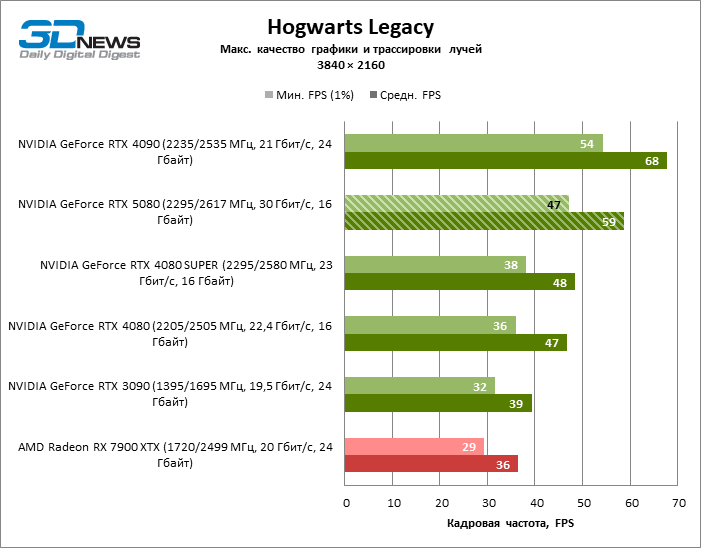
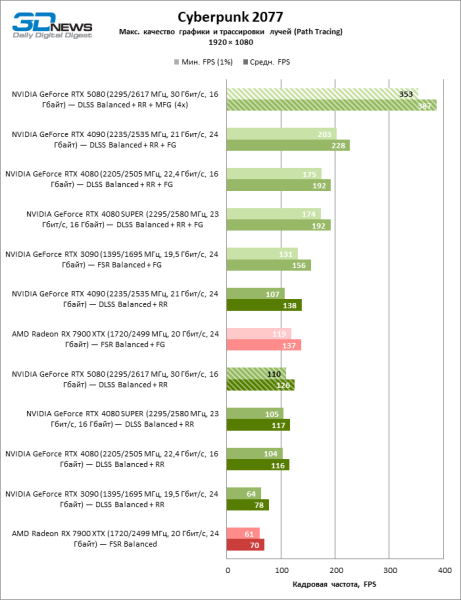
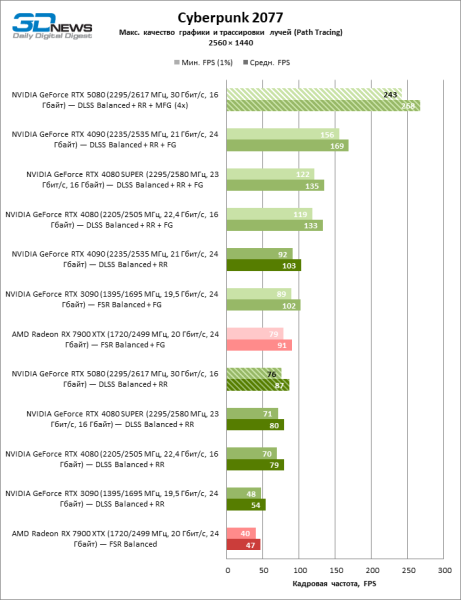
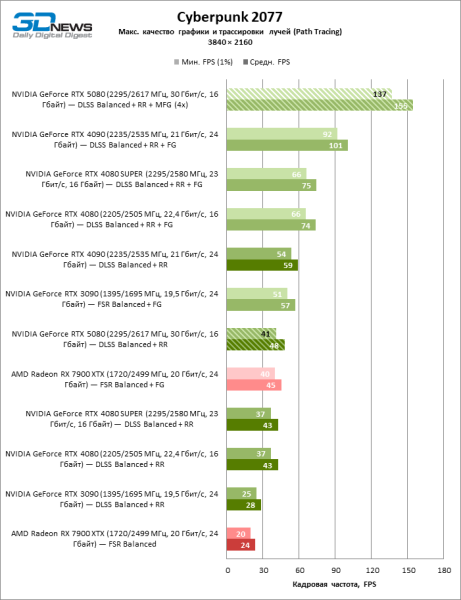
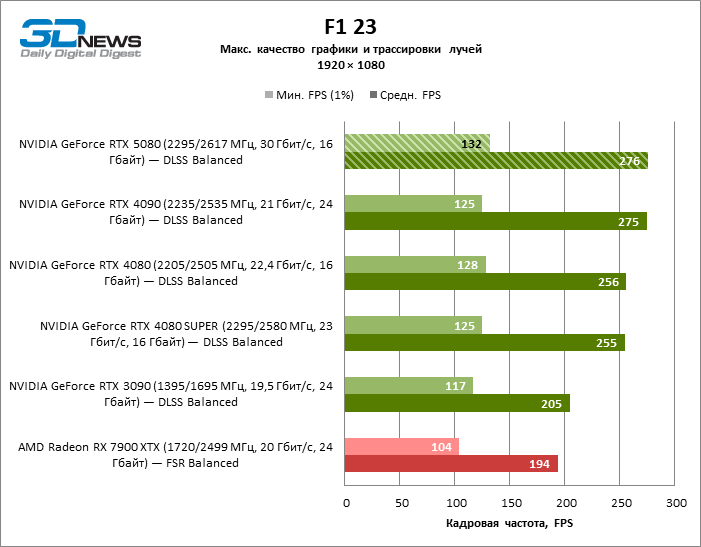
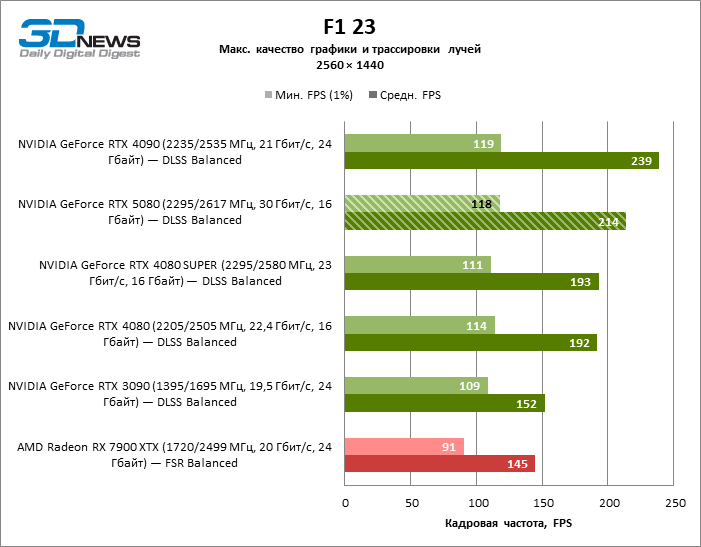
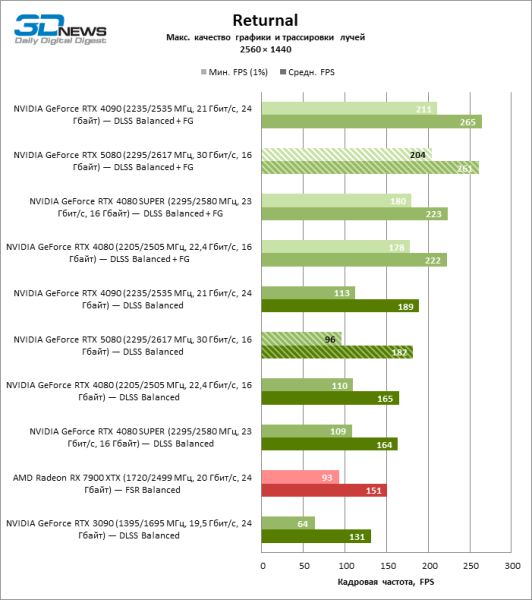
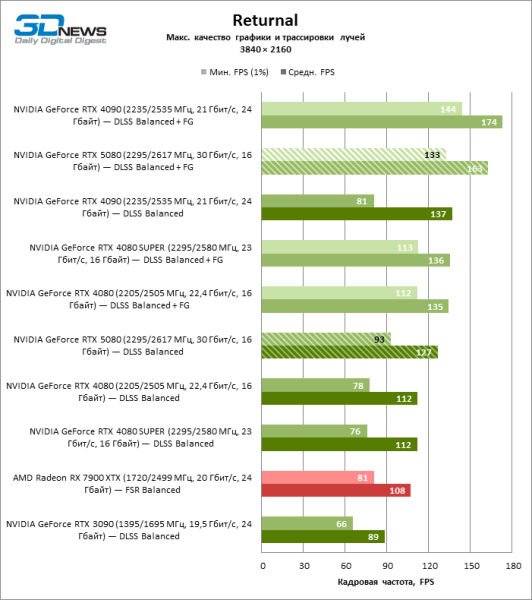
В свете инноваций архитектуры Blackwell, направленных на скорость трассировки лучей, резонно ожидать, что GeForce RTX 5080 лучше всего проявит себя именно в бенчмарках с RT, и отчасти это так. Полностью трассированные игры работают с фреймрейтом как минимум 57 FPS при разрешении 1080p, а гибридный рендеринг позволил RTX 5080 вплотную приблизиться к отметке 60 FPS на 4К-экране без масштабирования и генерации кадров.
| 1920 × 1080 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 78 / 83 | 46 / 55 | 67 / 72 | 69 / 72 | 88 / 95 | 47 / 50 |
| Black Myth: Wukong | 49 / 57 | 21 / 25 | 40 / 48 | 41 / 50 | 56 / 65 | 11 / 14 |
| Cyberpunk 2077 | 50 / 65 | 33 / 44 | 47 / 59 | 47 / 59 | 65 / 77 | 28 / 33 |
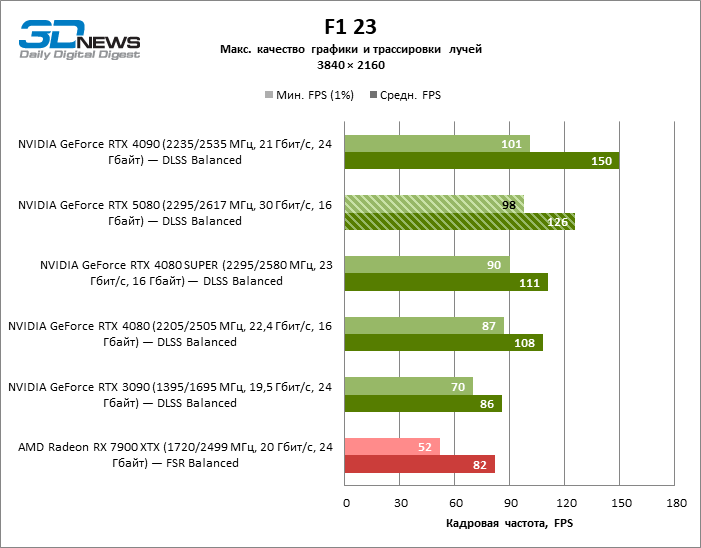
| F1 23 | 112 / 183 | 97 / 125 | 112 / 161 | 105 / 163 | 112 / 209 | 74 / 119 |
| Hogwarts Legacy | 124 / 153 | 88 / 106 | 104 / 125 | 106 / 129 | 141 / 166 | 83 / 99 |
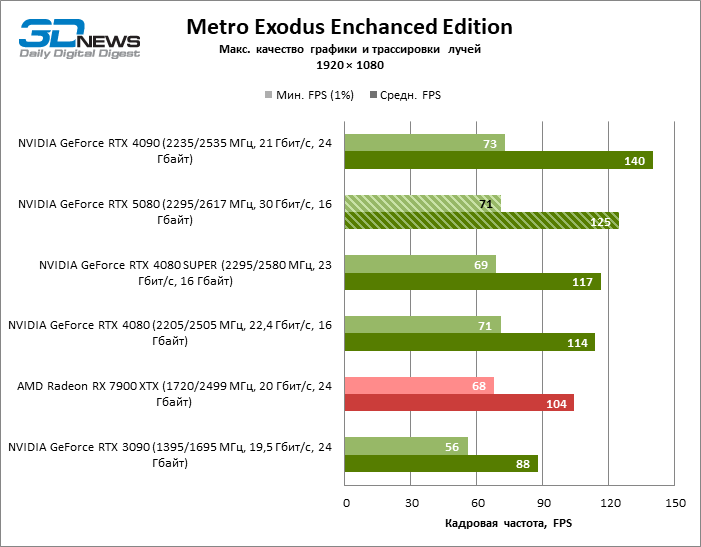
| Metro Exodus Enchanced Edition | 71 / 125 | 56 / 88 | 71 / 114 | 69 / 117 | 73 / 140 | 68 / 104 |
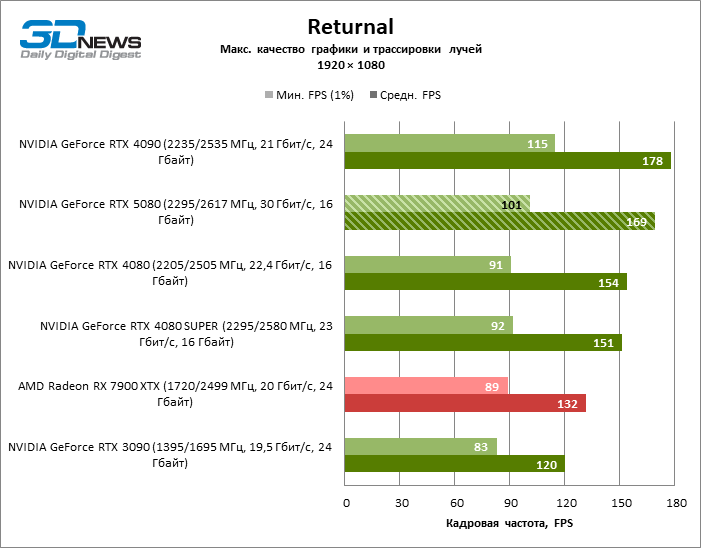
| Returnal | 101 / 169 | 83 / 120 | 91 / 154 | 92 / 151 | 115 / 178 | 89 / 132 |
| Макс. | −29% | −9% | −6% | +18% | −17% | |
| Средн. | −35% | −12% | −11% | +12% | −39% | |
| Мин. | −56% | −18% | −16% | +5% | −75% | |
| 2560 × 1440 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 53 / 57 | 33 / 37 | 46 / 49 | 44 / 49 | 63 / 66 | 30 / 33 |
| Black Myth: Wukong | 32 / 37 | 13 / 16 | 26 / 32 | 27 / 33 | 36 / 44 | 6 / 9 |
| Cyberpunk 2077 | 35 / 42 | 23 / 27 | 30 / 35 | 31 / 36 | 43 / 49 | 17 / 20 |
| F1 23 | 87 / 120 | 65 / 81 | 83 / 103 | 85 / 105 | 99 / 144 | 47 / 77 |
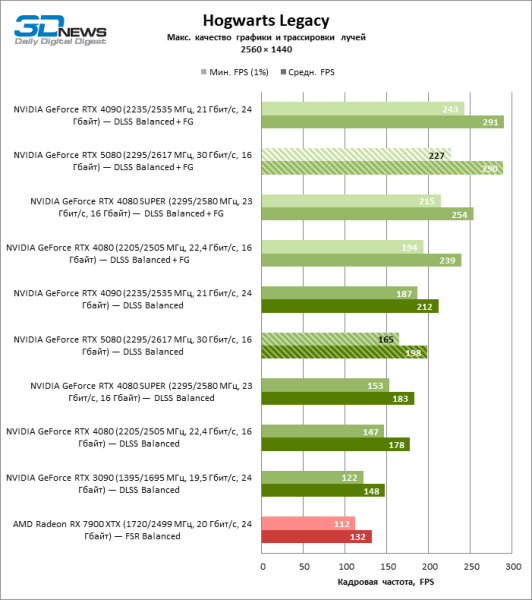
| Hogwarts Legacy | 85 / 105 | 58 / 73 | 70 / 87 | 73 / 89 | 96 / 118 | 56 / 69 |
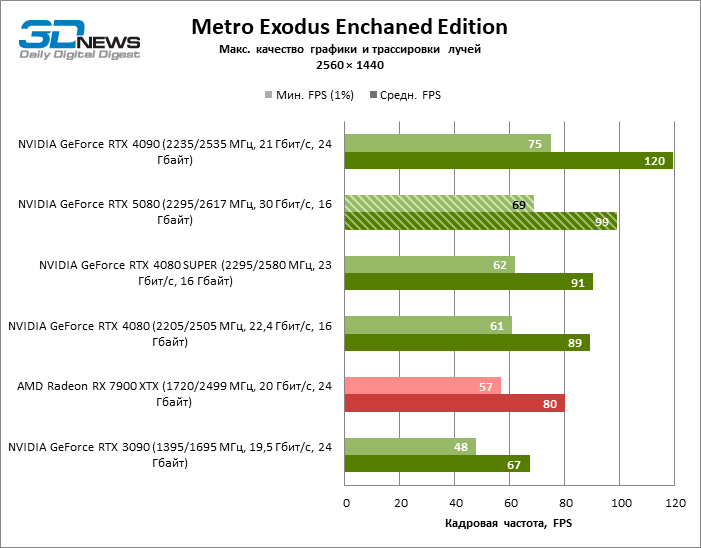
| Metro Exodus Enchanced Edition | 69 / 99 | 48 / 67 | 61 / 89 | 62 / 91 | 75 / 120 | 57 / 80 |
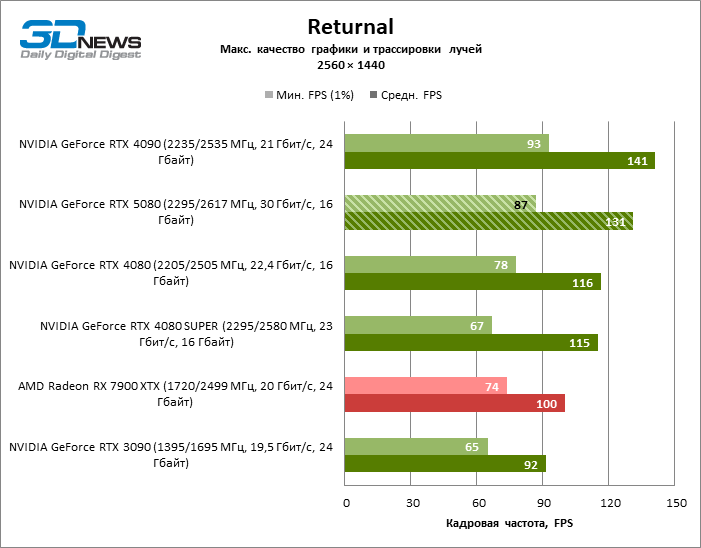
| Returnal | 87 / 131 | 65 / 92 | 78 / 116 | 67 / 115 | 93 / 141 | 74 / 100 |
| Макс. | −30% | −10% | −8% | +21% | −19% | |
| Средн. | −36% | −14% | −12% | +16% | −40% | |
| Мин. | −57% | −17% | −15% | +8% | −76% | |
| 3840 × 2160 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 27 / 29 | 17 / 19 | 23 / 25 | 23 / 25 | 32 / 34 | 14 / 16 |
| Black Myth: Wukong | 16 / 19 | 6 / 8 | 13 / 16 | 13 / 16 | 19 / 23 | 3 / 4 |
| Cyberpunk 2077 | 16 / 20 | 11 / 13 | 14 / 16 | 14 / 17 | 21 / 24 | 8 / 9 |
| F1 23 | 42 / 59 | 31 / 40 | 41 / 50 | 42 / 52 | 60 / 73 | 23 / 38 |
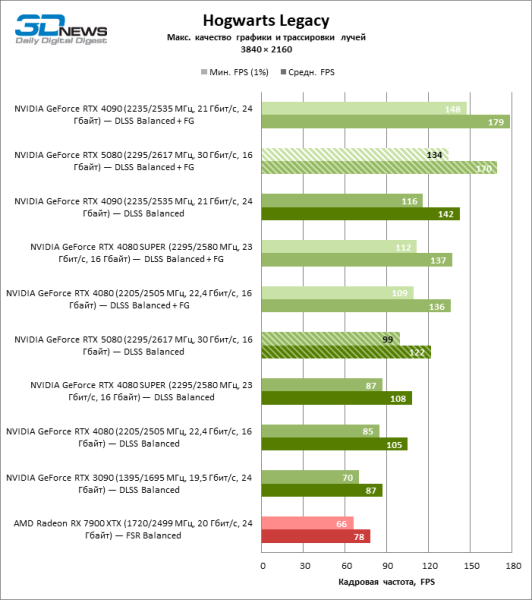
| Hogwarts Legacy | 47 / 59 | 32 / 39 | 36 / 47 | 38 / 48 | 54 / 68 | 29 / 36 |
| Metro Exodus Enchanced Edition | 45 / 60 | 29 / 41 | 41 / 53 | 34 / 55 | 56 / 74 | 35 / 46 |
| Returnal | 51 / 76 | 37 / 53 | 48 / 66 | 47 / 67 | 63 / 88 | 44 / 59 |
| Макс. | −30% | −12% | −8% | +24% | −22% | |
| Средн. | −36% | −16% | −14% | +19% | −43% | |
| Мин. | −58% | −20% | −19% | +15% | −79% | |
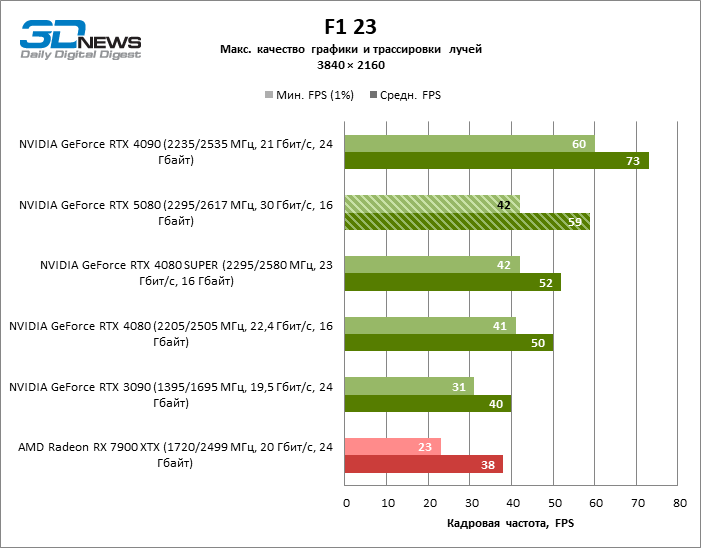
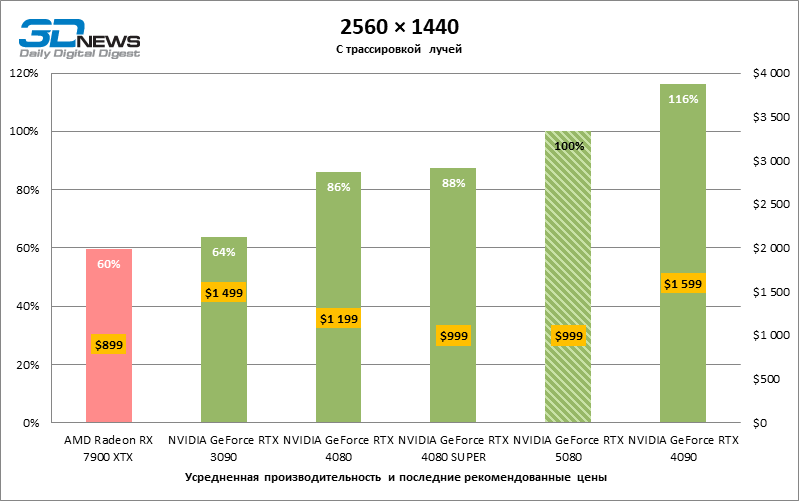
Рейтрейсинг избавил GeForce RTX 5080 от назойливой конкуренции со стороны Radeon RX 7900 XTX: усредненное преимущество «зеленой» видеокарты составляет 64–75 %, а в тестах с трассировкой путей и того больше. Дистанция между GeForce RTX 5080 и RTX 3090 также увеличилась до 53–57 % FPS. Увы, в рамках соседних поколений GPU разница между новой 80-й моделью и двумя версиями предшествующей увеличилась, но сводится к по-прежнему разочаровывающим 14–19 и 13–16 % кадровой частоты. GeForce RTX 4090, наоборот, защитил лидерскую позицию с отрывом от RTX 5080 на 12–19 %.
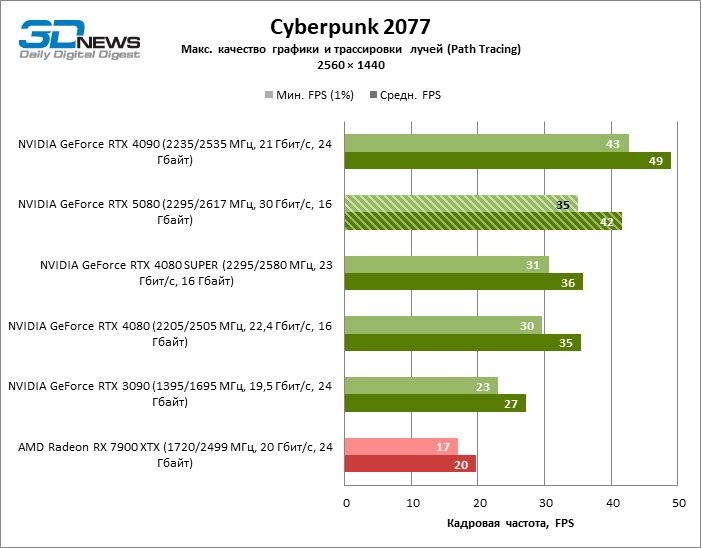
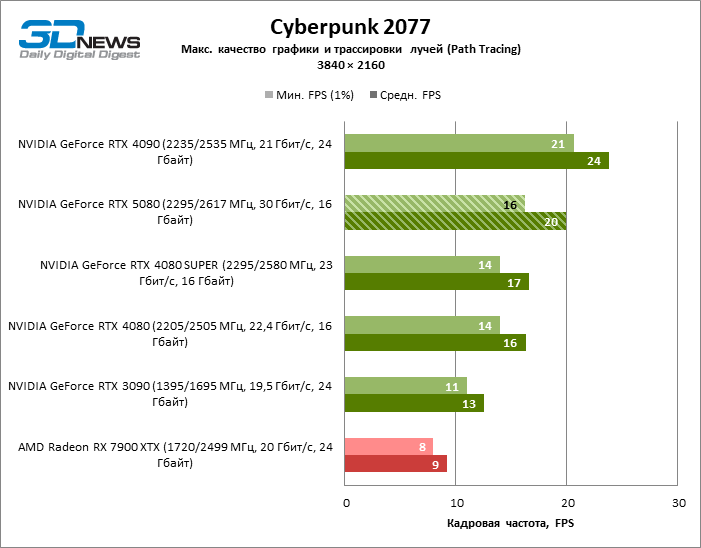
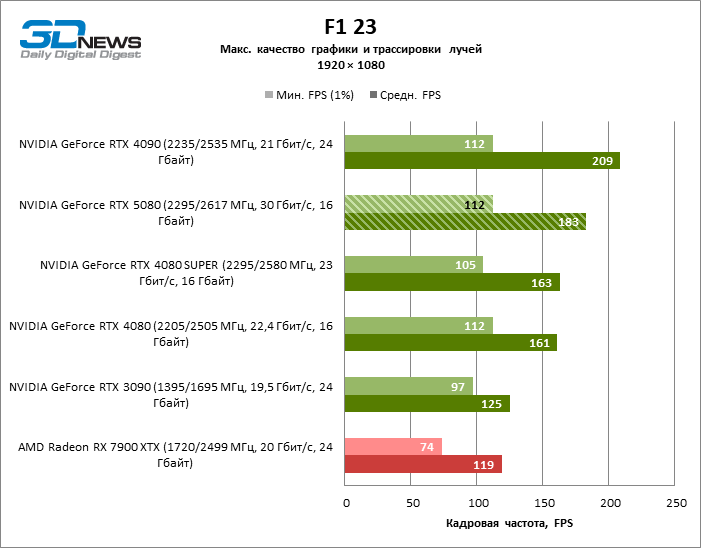
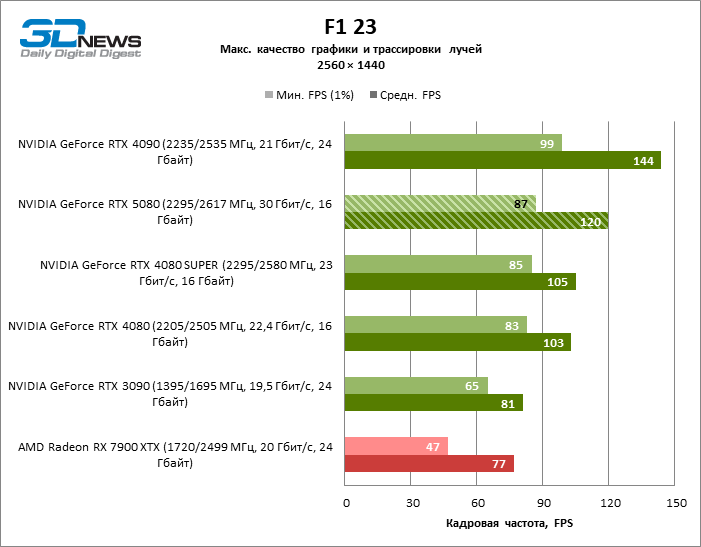

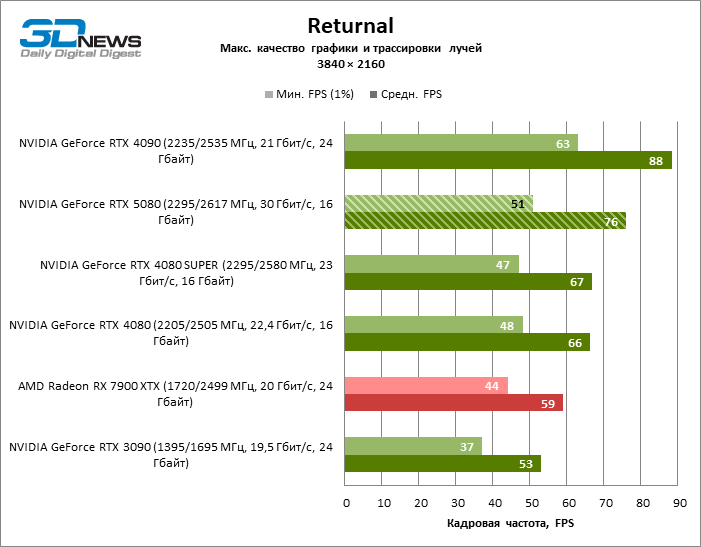
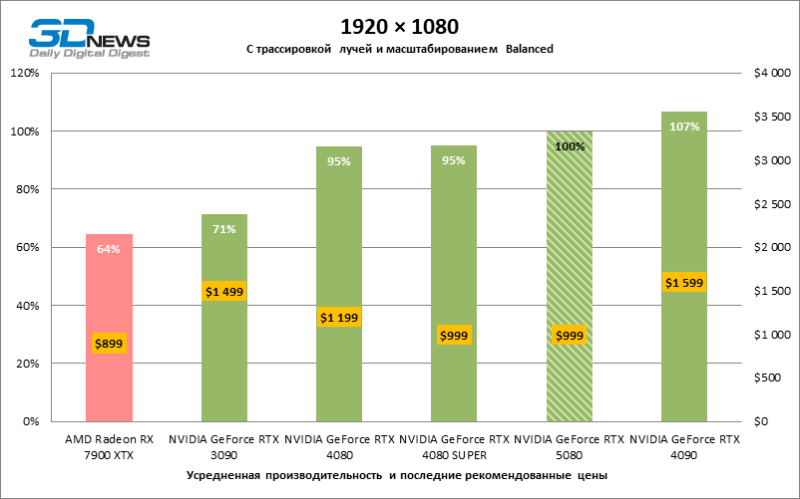
⇡#Игровые тесты с трассировкой лучей и масштабированием кадров
Масштабирование кадров с умеренным коэффициентом (Balanced) вывело GeForce RTX 5080 на уровень выше 100 FPS в играх с гибридным рендерингом на 4К-экране и более 60 FPS — в полностью трассированных бенчмарках при разрешении 1440p. Все ускорители NVIDIA выполнили тесты с использованием DLSS Ray Reconstruction, если эта функция поддерживается игрой.
| 1920 × 1080 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 124 / 133 | 88 / 95 | 117 / 126 | 118 / 127 | 145 / 156 | 81 / 85 |
| Black Myth: Wukong | 83 / 98 | 42 / 51 | 73 / 90 | 74 / 90 | 90 / 109 | 24 / 31 |
| Cyberpunk 2077 | 110 / 126 | 64 / 78 | 104 / 116 | 105 / 117 | 107 / 138 | 61 / 70 |
| F1 23 | 132 / 276 | 117 / 205 | 128 / 256 | 125 / 255 | 125 / 275 | 104 / 194 |
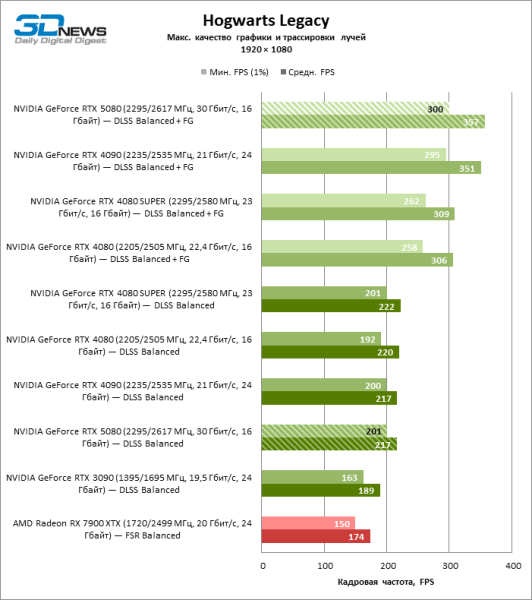
| Hogwarts Legacy | 201 / 217 | 163 / 189 | 192 / 220 | 201 / 222 | 200 / 217 | 150 / 174 |
| Metro Exodus Enchanced Edition | 80 / 148 | 67 / 113 | 79 / 139 | 81 / 142 | 79 / 158 | Н/Д |
| Returnal | 97 / 205 | 100 / 157 | 110 / 197 | 108 / 194 | 107 / 212 | 123 / 175 |
| Макс. | −13% | +1% | +2% | +17% | −15% | |
| Средн. | −29% | −5% | −5% | +7% | −36% | |
| Мин. | −48% | −8% | −8% | 0% | −68% | |
| 2560 × 1440 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 96 / 102 | 65 / 73 | 92 / 99 | 94 / 100 | 120 / 127 | 61 / 65 |
| Black Myth: Wukong | 63 / 75 | 30 / 35 | 56 / 67 | 56 / 68 | 71 / 86 | 17 / 22 |
| Cyberpunk 2077 | 76 / 87 | 48 / 54 | 70 / 79 | 71 / 80 | 92 / 103 | 40 / 47 |
| F1 23 | 118 / 214 | 109 / 152 | 114 / 192 | 111 / 193 | 119 / 239 | 91 / 145 |
| Hogwarts Legacy | 165 / 198 | 122 / 148 | 147 / 178 | 153 / 183 | 187 / 212 | 112 / 132 |
| Metro Exodus Enchanced Edition | 75 / 134 | 63 / 98 | 77 / 124 | 79 / 128 | 77 / 149 | Н/Д |
| Returnal | 96 / 182 | 64 / 131 | 110 / 165 | 109 / 164 | 113 / 189 | 93 / 151 |
| Макс. | −25% | −3% | −2% | +25% | −17% | |
| Средн. | −33% | −9% | −7% | +13% | −39% | |
| Мин. | −53% | −11% | −10% | +4% | −71% | |
| 3840 × 2160 | ||||||
|---|---|---|---|---|---|---|
| NVIDIA GeForce RTX 5080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4080 | NVIDIA GeForce RTX 4080 SUPER | NVIDIA GeForce RTX 4090 | AMD Radeon RX 7900 XTX | |
| Alan Wake 2 | 57 / 62 | 41 / 46 | 57 / 62 | 59 / 63 | 78 / 84 | 34 / 37 |
| Black Myth: Wukong | 39 / 45 | 17 / 20 | 33 / 39 | 33 / 40 | 44 / 53 | 8 / 11 |
| Cyberpunk 2077 | 41 / 48 | 25 / 28 | 37 / 43 | 37 / 43 | 54 / 59 | 20 / 24 |
| F1 23 | 98 / 126 | 70 / 86 | 87 / 108 | 90 / 111 | 101 / 150 | 52 / 82 |
| Hogwarts Legacy | 99 / 122 | 70 / 87 | 85 / 105 | 87 / 108 | 116 / 142 | 66 / 78 |
| Metro Exodus Enchanced Edition | 72 / 102 | 50 / 69 | 62 / 91 | 63 / 92 | 77 / 119 | Н/Д |
| Returnal | 93 / 127 | 66 / 89 | 78 / 112 | 76 / 112 | 81 / 137 | 81 / 108 |
| Макс. | −26% | 0% | +2% | +35% | −15% | |
| Средн. | −35% | −11% | −9% | +19% | −42% | |
| Мин. | −56% | −14% | −12% | +8% | −76% | |
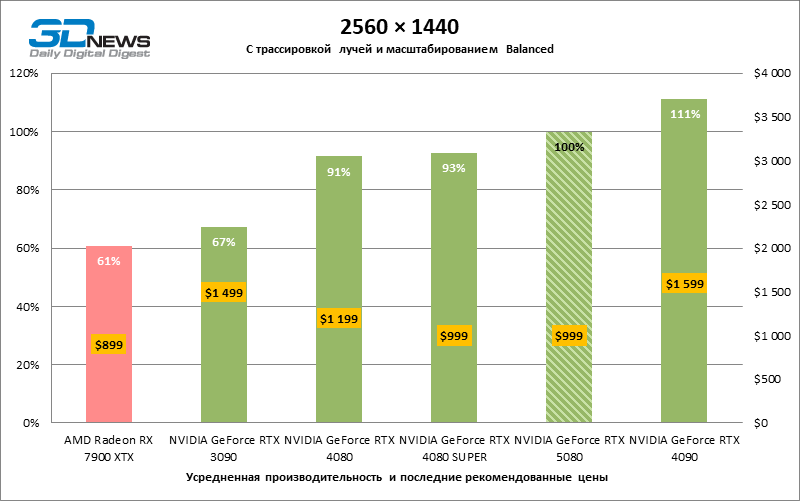
Под сниженной благодаря апскейлингу нагрузкой соперничающие видеокарты вновь сблизились друг с другом. GeForce RTX 5080 по-прежнему опережает GeForce RTX 3090 и Radeon RX 7900 XTX на огромные величины 40–54 и 55–72 % FPS. А вот преимущество новинки перед GeForce RTX 4080 и RTX 4080 SUPER уменьшилось до скромных 6–12 и 5–10 % FPS соответственно. Впрочем, и GeForce RTX 4090 в этих, наиболее реалистичных для мощных видеокарт, условиях гейминга превосходит RTX 5080 всего лишь на 7–19 %.
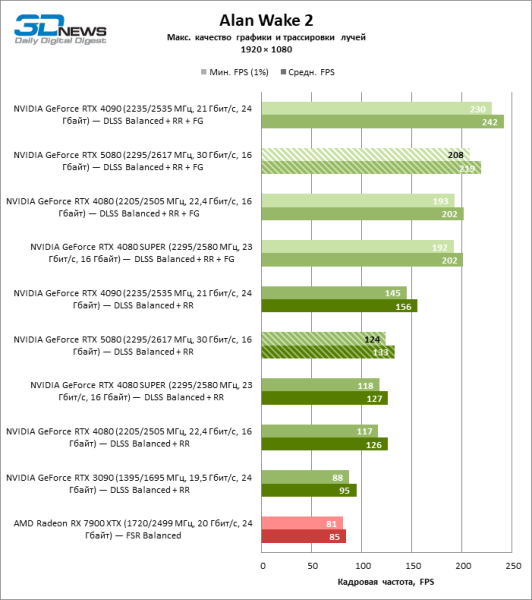
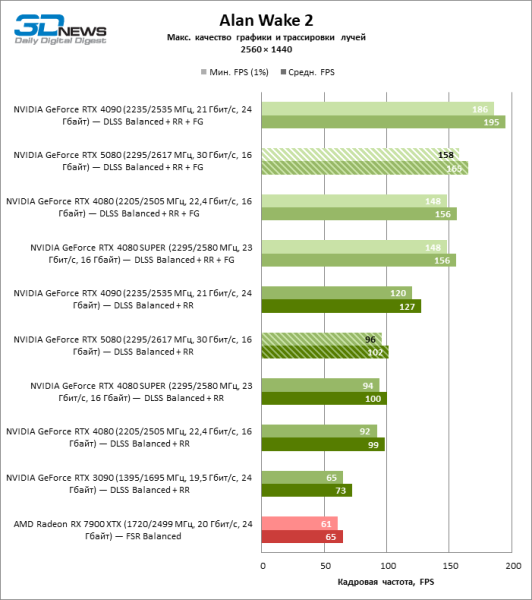
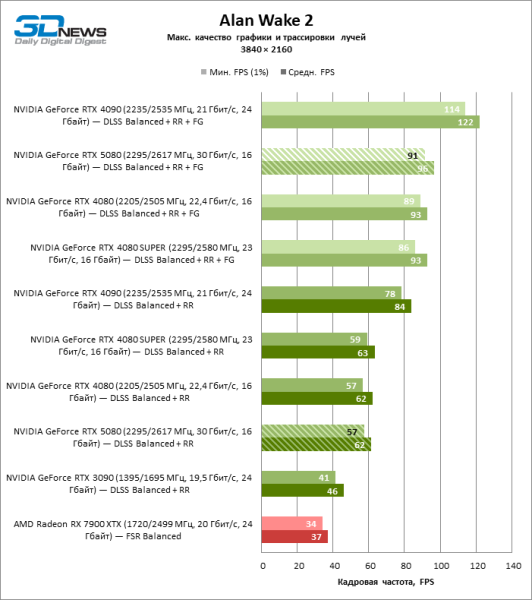
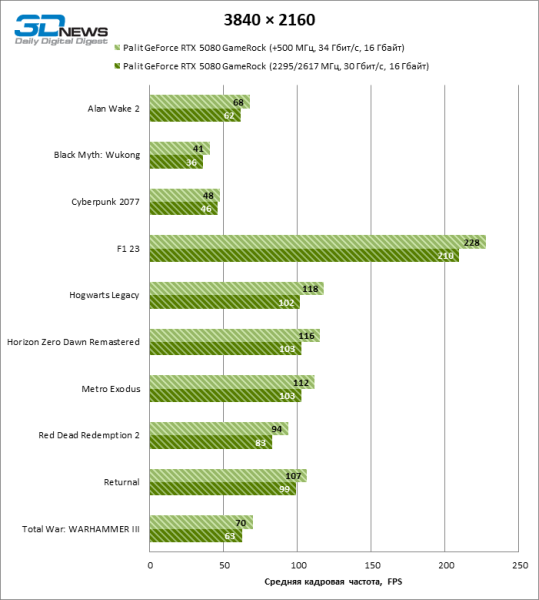
⇡#Игровые тесты в разгоне
В силу того, как чипы Blackwell управляют тактовой частотой, формальная прибавка в 500 МГц (и 457 МГц по данным мониторинга) говорит далеко не все о работе GPU «под капотом». Как бы то ни было, для видеокарты без неисчерпанного резерва мощности Palit GameRock разгоняется замечательно: в растеризованых играх на 4К-экране фреймрейт увеличился в среднем на 11 %, что вплотную приблизило GeForce RTX 5080 к версии GeForce RTX 4090 с околореференсными частотами.
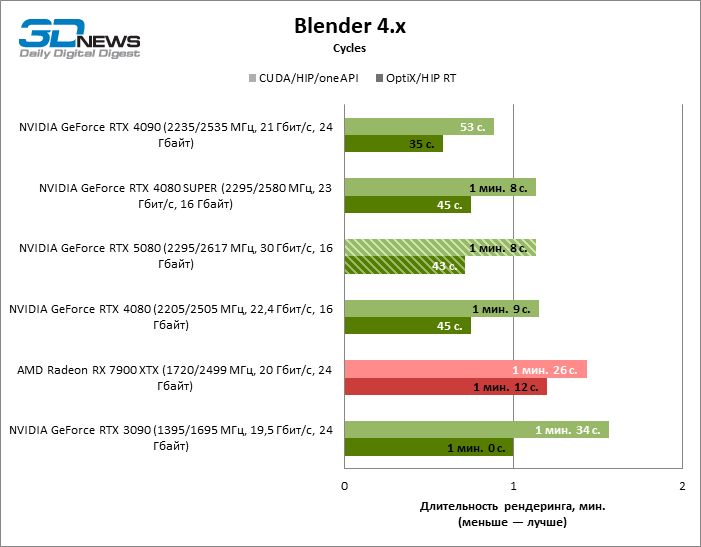
⇡#Тесты в рабочих приложениях
Рендеринг в Blender является мерилом сырой производительности GPU в вещественночисленных расчетах, а в этом отношении GeForce RTX 5080 сделал лишь формальный шаг вперед от RTX 4080 SUPER. Как следствие, новинка имеет крошечное преимущество перед старыми 80-ми моделями при использовании аппаратного рейтрейсинга, но по большому счету между тремя ускорителями практически нет существенной разницы. Ну а GeForce RTX 4090 остается безоговорочным лидером в задачах такого рода.
А вот бенчмарк кодирования/декодирования в Premiere Pro поставил GeForce RTX 5080 на первое место среди участников тестирования благодаря высокой скорости работы с форматами H.264 и HEVC. Однако надо заметить, что оно досталось бы Radeon RX 7900 XTX, если бы не низкий результат в тестах RAW.
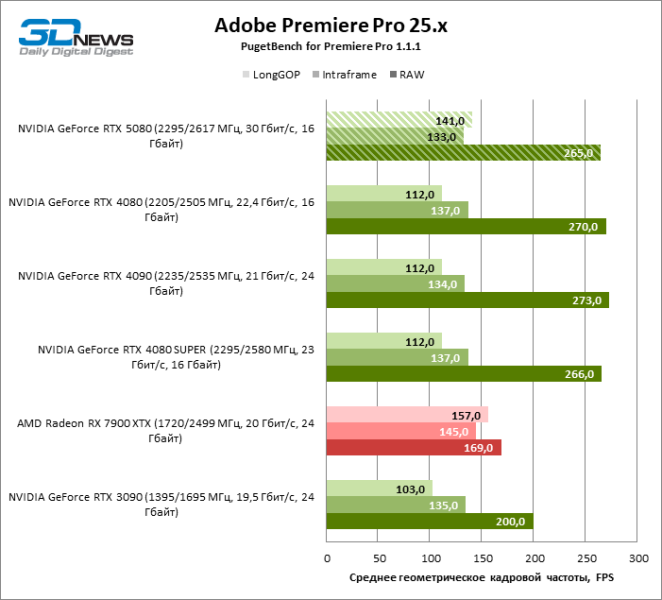
Старшие модели NVIDIA образуют плотную группу на графике производительности GPU-эффектов в Premiere Pro, а GeForce RTX 5080 достиг таких же результатов, как RTX 4080 SUPER.
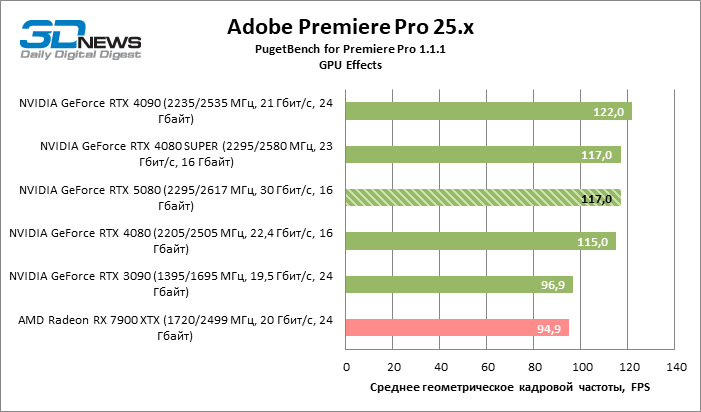
Тест с использованием различных форматов видео в DaVinci Resolve принес еще одну победу GeForce RTX 5080 с небольшим отрывом от прежнего чемпиона — Radeon RX 7900 XTX.
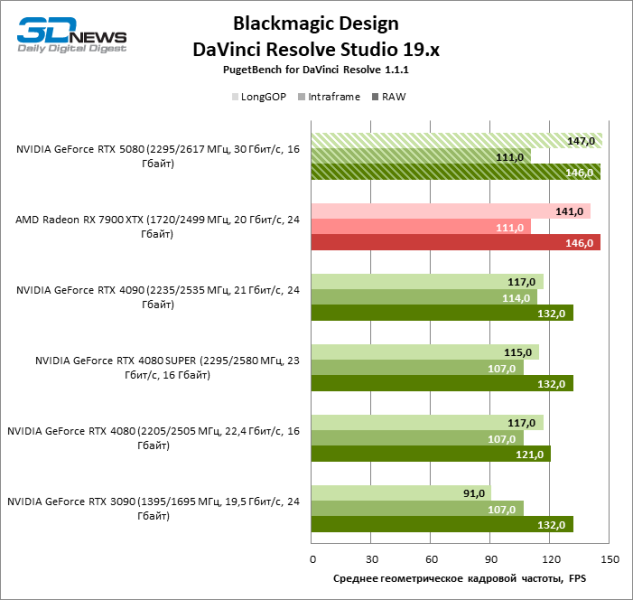
По скорости рендеринга GPU-эффектов в DaVinci Resolve новинка также обошла Radeon RX 7900 XTX и отстает лишь от GeForce RTX 4090, однако «красный» флагман не уступил лидерство в бенчмарке Fusion.
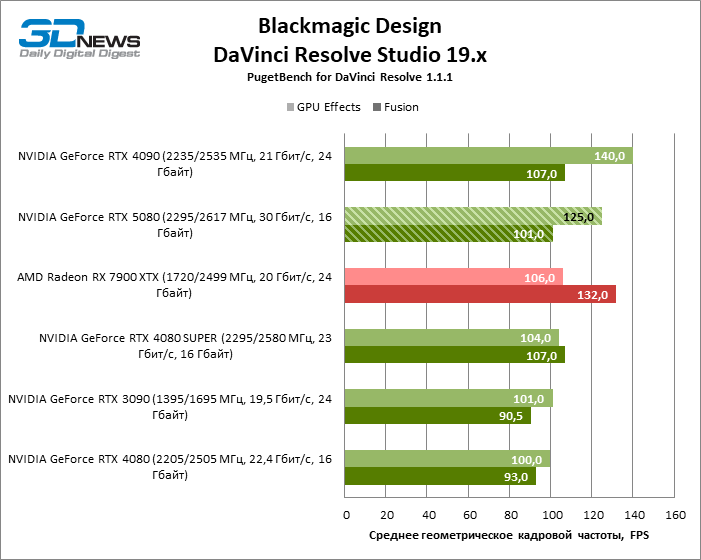
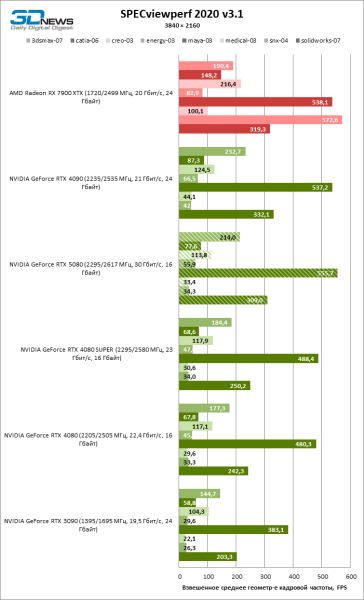
Наконец, GeForce RTX 5080 продемонстрировал такой же профиль быстродействия в CAD-приложениях, как видеокарты 40-й серии. По усредненной оценке RTX 5080 занимает позицию между RTX 4080 SUPER и RTX 4090, но все «зеленые» ускорители не идут ни в какое сравнение с Radeon RX 7900 XTX.
⇡#Кодирование/декодирование видео
Аппаратный декодер NVDEC, который и раньше не жаловался на быстродействие, получил небольшую прибавку к скорости работы с HEVC, VP9 и AV1. А главное, кадровая частота H.264 увеличилась более чем в два раза. Теперь NVIDIA лидирует во всех тестах декодирования, за исключением AV1 с разрешением 1080p и VP9, где первое место занимает интеловский QuickSync на плате Arc B580.
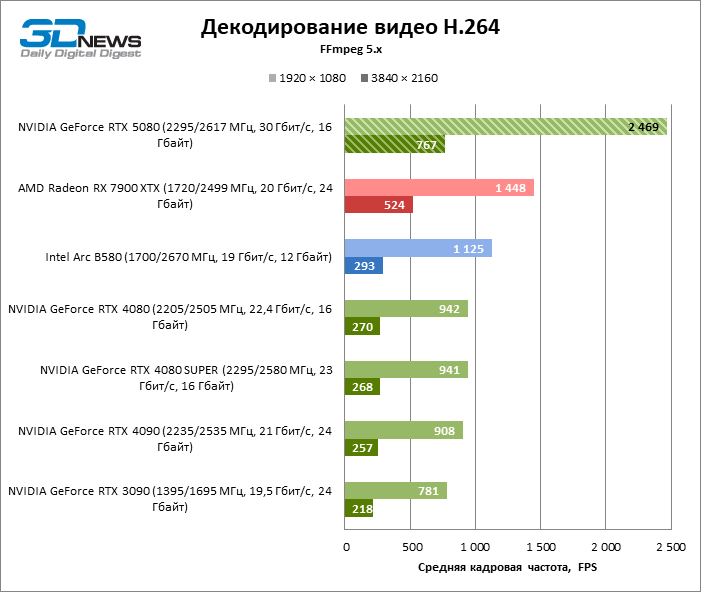
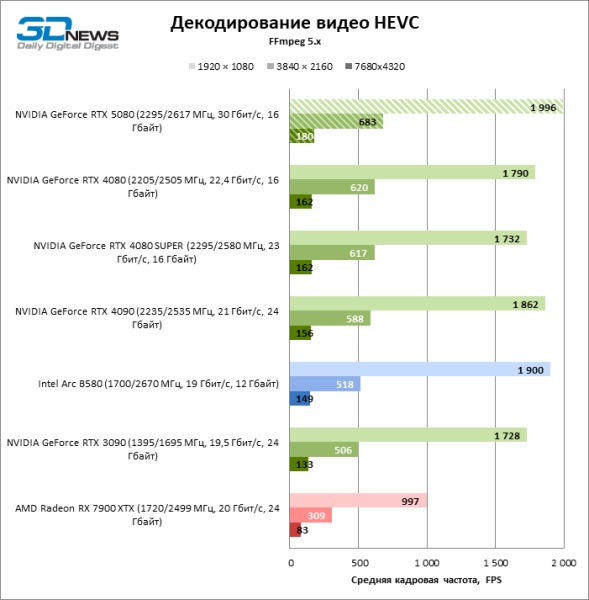
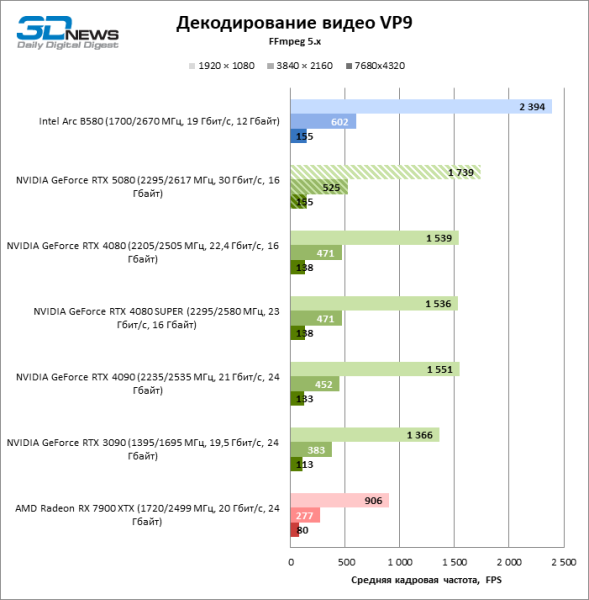
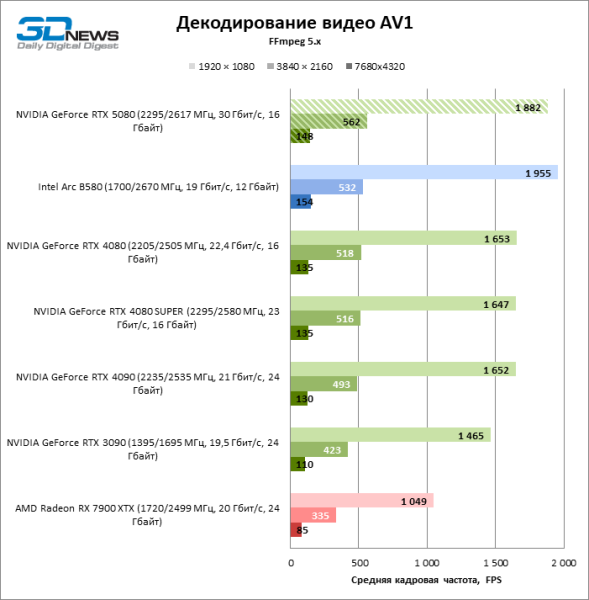
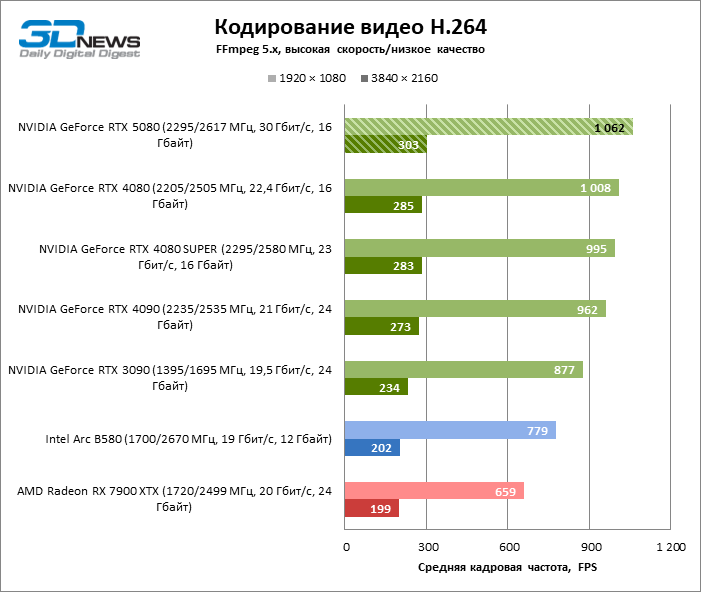
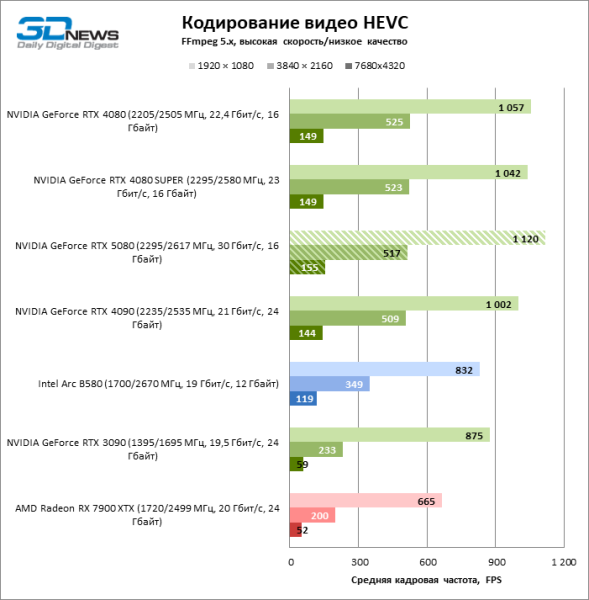
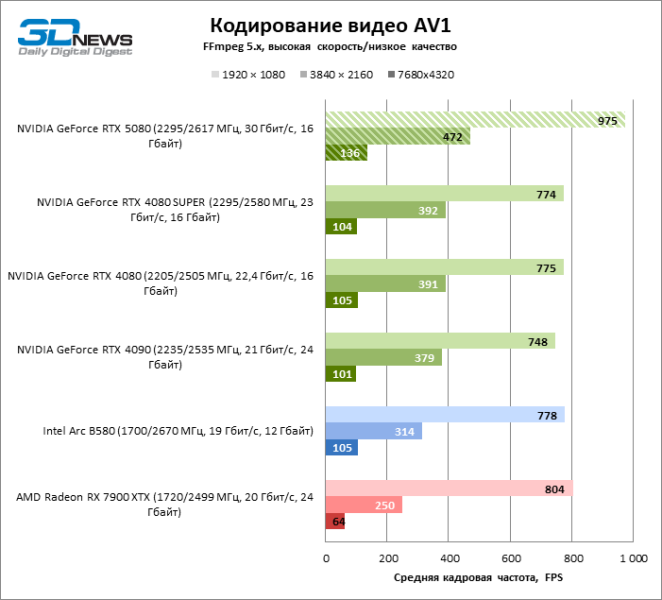
Что касается аппаратного кодирования, то GeForce RTX 5080 не удалось продемонстрировать существенного преимущества перед старшими моделями 40-й серии в бенчмарках H.264 и HEVC, а вот скорость экспорта в AV1 заметно увеличилась (особенно при разрешении 8К). В этой группе задач RTX 5080 безоговорочно опережает решения Intel и AMD.
⇡#Производительность на ватт
Несмотря на все усовершенствования чипов Blackwell, призванные увеличить энергоэффективность в условиях прежней фотолитографической нормы, сравнение GeForce RTX 5080 с RTX 4080 SUPER по средней кадровой частоте (как в растеризованных, так и в трассированных играх) на ватт бюджета мощности закончилось не в пользу новинки. А у базовой версии RTX 4080 она выигрывает лишь 1–2 %. Любопытно и то, что Radeon RX 7900 XTX оказался полным эквивалентом GeForce RTX 5080 по удельному быстродействию в растеризации, хотя предсказуемо уступает ему 39 % FPS на ватт в играх с гибридным рендеригингом или трассировкой путей.
| Производитель | NVIDIA | AMD | ||||
|---|---|---|---|---|---|---|
| Модель | GeForce RTX 5080 | GeForce RTX 3090 | GeForce RTX 4080 | GeForce RTX 4080 SUPER | GeForce RTX 4090 | Radeon RX 7900 XTX |
| Графический процессор | GB203 | GA102 | AD103 | AD103 | AD102 | Navi 31 XTX |
| Микроархитектура | Blackwell | Ampere | Ada Lovelace | Ada Lovelace | Ada Lovelace | RDNA 3 |
| Техпроцесс, нм | TSMC 4NP | Samsung 8N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC N5/N6 |
| Средняя потребляемая мощность (FurMark), Вт | 397 | 370 | 332 | 317 | 454 | 372 |
| Производительность/Вт (без трассировки лучей) | 100% | −25% | +2% | +8% | −1% | +0% |
| Производительность/Вт (с трассировкой лучей) | 100% | −31% | +1% | +8% | +4% | −39% |
⇡#Сводные результаты игровых тестов без трассировки лучей
⇡#Сводные результаты игровых тестов с трассировкой лучей
⇡#Сводные результаты игровых тестов с трассировкой лучей и масштабированием кадров
⇡#Выводы
Появление GPU новой архитектуры — всегда большое и волнующее событие, особенно сейчас, когда чипмейкеры все еще осваивают трассировку лучей и нейросети в игровом рендеринге. Однако чистая производительность видеокарт уже не может нарастать прежними темпами. Инженеры NVIDIA сделали многое, чтобы извлечь максимум из фотолитографии 5 нм, а функциональные нововведения логики Blackwell — в первую очередь, новая версия DLSS и нейронные шейдеры — стали еще одним шагом в сторону от парадигмы рендеринга грубой силой. Причем генерацией множественных кадров с помощью DLSS 4 можно воспользоваться уже сейчас даже в тех играх, которые не предлагают этой функции нативно.
Проблема в том, что MFG действительно обеспечивает многократный «бесплатный» рост кадровой частоты, но в лучшем случае не способствует уменьшению задержки ввода по сравнению с базовым фреймрейтом. Поэтому чистая производительность GPU по-прежнему важна, а именно ее GeForce RTX 5080 не хватает, чтобы отработать рекомендованную стоимость в $999. Отними у чипа Blackwell генерацию множественных кадров, и мы получим второе издание RTX 4080 SUPER. В самых благоприятных условиях (игры на 4К-экране с рейтрейсингом) RTX 5080 удалось сдвинуть планку быстродействия лишь на 16 %. Этого не хватило даже для того, чтобы выйти на уровень прежнего флагмана — GeForce RTX 4090, что является беспрецедентным провалом для 80-х моделей NVIDIA. Другой пощечиной стало тесное соперничество с Radeon RX 7900 XTX в растеризованных бенчмарках. Впрочем, зачем покупать настолько дорогие видеокарты, если не для игр с RT?
В защиту новинки можно возразить, что она обладает заведомо лучшим соотношением возможностей и цены по сравнению с GeForce RTX 4090, который уже давно оторвался от своей MSRP. Однако видеокарты 50-й серии наверняка постигнет такой же дефицит. GeForce RTX 5080 — идеальный пример того, что происходит в отсутствии конкуренции, которая покинула рынок дискретных GPU и точно не вернется в текущем цикле.
А вот ускоритель Palit GameRock, который представляет GeForce RTX 5080 в обзоре, не дал ни малейшего повода для критики. Несмотря на энергопотребление вплоть до 400 Вт, устройство работает тихо и удивительно продуктивно разгоняется (что в немалой степени является заслугой кремния Blackwell) — лишь бы в корпусе хватило места для такой огромной видеокарты.


